ljn
How Change Data Capture (CDC) enables real-time data replication & integration.
Written by
Armend Avdijaj
-

Change Data Capture: A quick overview
Change data capture (CDC) extracts each change event (insert, update, delete) in a database. We often use CDC to replicate between databases in near real-time or create an event stream for downstream processing.
There are two types of database technology: relational databases and NoSQL databases. In relational databases, events are generated and stored on the database server in the form of Database logs that can be processed to create a stream. NoSQL databases can send logs or event streams to a target storage location.
In this article, we will focus our discussion on relational databases.
Why CDC?
Modern data architectures often use diverse data stores tailored to specific needs. For instance:
Transactional Databases: These systems are designed to handle many short online transactions, ensuring data consistency. Examples include PostgreSQL and MySQL. They are often used for operational data, such as order processing in e-commerce or user management in web applications.
Data Warehouses are systems optimized for analytical queries rather than transactions. They aggregate data from multiple sources for business intelligence and reporting. Examples include Snowflake and Redshift.
Search Engines like Elasticsearch provide fast retrieval for specific use cases, such as product searches in online stores.
These systems must often sync data seamlessly. However, traditional ETL processes that execute periodic data extractions are inefficient and resource-intensive, as they process the entire dataset rather than focusing on recent changes. CDC solved this problem because it is a method that efficiently detects and replicates changes, ensuring real-time synchronization without unnecessary overhead.
CDC offers several advantages for organizations looking to modernize their data infrastructure:
Near Real-Time Data Replication: CDC enables low-latency data replication between databases. It is particularly useful for disaster recovery, reporting, and analytics scenarios, where up-to-date data is critical.
Reduced Load on Source Systems: Unlike batch-based ETL processes, which periodically query the entire database, CDC only processes changes. It reduces the load on the source database and improves overall system performance.
Event-Driven Architectures: CDC can be used to create event streams that power event-driven architectures. For example, a change in a customer table could trigger an event that updates a recommendation engine in real-time.
Auditing and Compliance: CDC provides a detailed history of changes, which can be invaluable for auditing and compliance purposes. By recording every change, organizations can track who made what changes and when.
Simplified Data Integration: CDC simplifies integrating data from multiple sources. By capturing only the changes, the complexity and volume of data that needs to be processed are reduced.
Use Cases for CDC
CDC is a versatile technology with a wide range of use cases. Here are a few examples:
Data Replication: CDC is commonly used to replicate data between databases for purposes like disaster recovery, load balancing, and geographic distribution.
Real-Time Analytics: By capturing changes and streaming them to an analytics platform, organizations can perform real-time analysis on their data.
Microservices Integration: In a microservices architecture, CDC can be used to propagate changes from a shared database to individual services, ensuring data consistency across the system.
Data Warehousing: CDC simplifies the process of loading data into a data warehouse. Instead of performing full table scans, only the changes are transferred, reducing latency and resource usage.
Audit Trails: CDC can be used to create detailed audit trails, tracking every change made to a database. This is particularly useful for industries with strict compliance requirements.
How CDC Works in Relational Databases
At its core, the CDC relies on the database's transaction log (also known as the write-ahead log or redo log) to track changes. Every time a row is inserted, updated, or deleted, the database records this event in its transaction log. This log is primarily used for recovery purposes, ensuring data integrity in case of a crash. However, CDC leverages this log to capture and propagate changes to other systems.
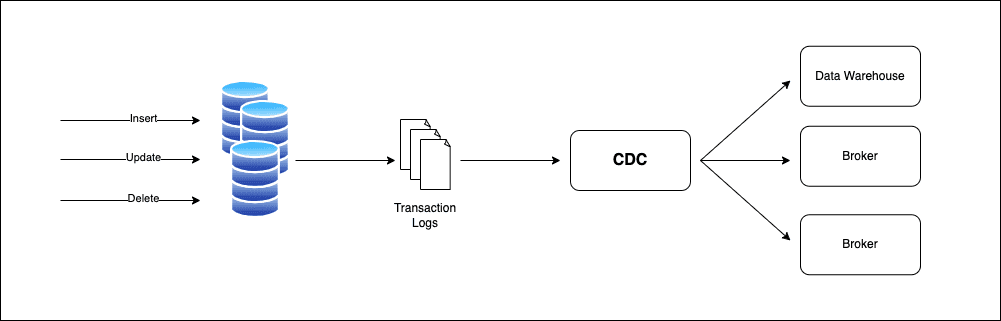
Key Components of CDC
Transaction Logs: As mentioned, the transaction log is the source of truth for CDC. It contains a sequential record of all changes made to the database. Each log entry includes the operation type (insert, update, delete), the affected table, row data (before and after the change), and a timestamp.
CDC Mechanisms: Relational databases provide different mechanisms to implement the CDC. These can be broadly categorized into Trigger-Based CDC, Log-Based CDC, Timestamp-Based CDC, and Diff-based CDC. We will explore these different mechanisms in the next chapter.
Change Data Consumers: Once changes are captured, they need to be processed and sent to downstream systems. These consumers can include data warehouses, analytics platforms, event-driven microservices, or other databases.
CDC Mechanisms
Diff-Based CDC
This approach compares the current state of the database with a previous state to identify changes. This is typically done by querying the database at regular intervals and computing the differences between the two states. While this method is conceptually simple, it can be resource-intensive, especially for large datasets, as it requires scanning entire tables or datasets to detect changes. Diff-based CDC is often used in scenarios where log-based or trigger-based CDC is not feasible, such as when working with databases that lack robust transaction logs or when implementing CDC on legacy systems. However, it is generally less efficient and slower than log-based CDC, making it less suitable for real-time use cases.
Timestamp-Based CDC
This approach relies on a column in each table that records the last modification time (e.g., last_updated). By querying rows with a timestamp greater than the last recorded value, you can identify changes. However, this method may miss deletions and is less reliable for real-time use cases.
Trigger-Based CDC
This approach uses database triggers to capture changes. A trigger is a stored procedure that automatically executes in response to an event (e.g., an insert, update, or delete). While effective, trigger-based CDC can introduce overhead and impact database performance.
Log-Based CDC
This method reads changes directly from the transaction log. It is more efficient than trigger-based CDC because it doesn't interfere with the database's normal operations. Popular databases like PostgreSQL, MySQL, and SQL Server support log-based CDC.
CDC Mechanism Comparisons
CDC Mechanism | Pros | Cons |
|---|---|---|
Diff-Based CDC | Works with any database, even those without transaction logs.No need for triggers or log access. | Resource-intensive due to full table scans.High latency, as changes are detected periodically.Not suitable for real-time or high-volume systems. |
Timestamp-Based CDC | Simple to implement.Works with any database that supports timestamps.Lightweight compared to triggers. | Cannot capture deletions without additional logic.Relies on accurate timestamps, which may not always be reliable.Not suitable for real-time use cases. |
Trigger-Based CDC | Easy to implement.Works with any database that supports triggers.Captures changes at the row level. | Introduces performance overhead on the source database.Can slow down write operations.Complex to manage for large-scale systems. |
Log-Based CDC | High performance and low latency.Minimal impact on source database.Captures all changes, including deletions. | Requires access to database transaction logs.Complex to implement due to log format variations.May need specialized tools or libraries. |
CDC Implementation in PostgreSQL
If you are using PostgreSQL, here are examples that will help illustrate how each mechanism works in practice.
Diff-Based CDC
This approach compares the current state of the table with a previous state to identify changes.
Example:
Create a Snapshot Table:
Compare Snapshots:
Update the Snapshot:
Periodically, the current state of the table is compared with a snapshot of the previous state of identify changes. As stated in the previous section, this approach is resource-intensive and not suitable for real-time use cases.
Timestamped-Based CDC
This approach relies on a last_updated (or whatever field name you choose) column in the table to track changes. Example:
Every time a row is inserted or updated, the last_updated column is automatically set to the current timestamp. To capture changes, query the table for rows where last_updated is greater than the last recorded timestamp. Note that this approach cannot detect deletions unless you use a soft delete mechanism (e.g., an is_deleted column).
Trigger-Based CDC
In PostgreSQL, you can use triggers to capture changes and store them in a separate audit table. Example:
The trigger logs changes in the customers_audit table whenever a row is inserted, updated, or deleted in the customers table. The operation column indicates the type of change (I, U, or D), and the old_data and new_data columns store the row data before and after the change.
Log-Based CDC
PostgreSQL provides a feature called Logical Decoding (via the pg_logical extension) to capture changes from the transaction log (Write-Ahead Log or WAL). To use this feature you need to enable Logical Decoding.
Once you have done that you need to create a replication slot:
Then you consume the changes from the replication slot. You can use a custom script or Debezium. Example us pg_recvlogical:
Or if you want to write a custom script in Python, you can do the following:
The SELECT * FROM pg_logical_slot_get_changes('cdc_slot', NULL, NULL); fetches changes since the last read.
In this approach, PostgreSQL writes all changes to the WAL. Logical decoding extracts these changes and makes them available for consumption. Tools like Debezium or custom scripts can process these changes and send them to downstream systems.
CDC Implementation in MySQL
MySQL support multiple ways to implement CDC as well. But it has some limitations compared to PostgreSQL.
Diff-Based CDC
This approach compares the current state of the table with a previous state to identify changes. Examples:
Create a snapshot table
Compare snapshot
Update the snapshot
Periodically, the current state of the table is compared with a snapshot of the previous state to identify changes. This approach is resource-intensive and not suitable for real-time use cases.
Timestamp-Based CDC
This approach relies on a last_updated column in the table to track changes. Examples:
Every time a row is inserted or updated, the last_updated column is automatically set to the current timestamp. To capture changes, query the table for rows where last_updated is greater than the last recorded timestamp.
Trigger-Based CDC
In MySQL, you can use triggers to capture changes and store them in a separate audit table.
Every time a row is inserted, updated, or deleted in the customers table, the trigger logs the change in the customers_audit table. The operation column indicates the type of change (I, U, or D), and the old_data and new_data columns store the row data before and after the change.
Log-Based CDC
MySQL provides a feature called Binary Logs (binlogs) to capture changes. You can use tools like Debezium or mysqlbinlog to process these logs. Example:
Enable Binary Logging. Ensure binary logging is enabled in your MySQL configuration (
my.cnformy.ini) and don’t forget to restart the server to apply changes.Grant replication privileges
Read
BinlogChanges Usingmysqlbinlog
MySQL writes all changes to the binary log in row-based format. You can write a custom script or use tools like Debezium or Maxwell to process these logs and send them to downstream systems.
For instance, in Python you can run the following script:
Best Practices for Implementing CDC
To get the most out of CDC, consider the following best practices:
Choose the Right CDC Mechanism: Evaluate your use case and choose the CDC mechanism that best fits your needs. Log-based CDC is generally preferred for its efficiency, but trigger-based CDC may be simpler to implement in some cases.
Monitor Performance: CDC can introduce overhead, so it’s important to monitor the performance of your database and CDC pipeline. Use tools like Prometheus or Grafana to track key metrics.
Handle Schema Changes Gracefully: Ensure your CDC solution can handle schema changes without breaking. This may involve using tools that support schema evolution or implementing custom logic to manage changes.
Ensure Data Consistency: Use mechanisms like distributed transactions or idempotent processing to ensure data consistency across systems.
Plan for Scalability: Design your CDC pipeline to handle increasing volumes of data. Use distributed systems like Apache Kafka to buffer and process change events at scale.
Challenges of Implementing CDC
While CDC is powerful, it is not without its challenges. The following are few problem that you might face when implementing CDC on your projects.
Complexity of Log-Based CDC: Reading and interpreting transaction logs can be complex. Each database has its own log format, and parsing these logs requires specialized tools or libraries.
Performance Overhead: Although log-based CDC is more efficient than trigger-based CDC, it still introduces some overhead. For high-throughput systems, this overhead needs to be carefully managed.
Data Consistency: Ensuring data consistency across systems can be challenging, especially in distributed environments. Changes need to be applied in the correct order to avoid inconsistencies.
Schema Changes: CDC systems must handle schema changes gracefully. For example, if a column is added or removed, the CDC process should continue to function without breaking.
Latency and Backpressure: In high-volume systems, the rate of change events can overwhelm downstream consumers. Proper buffering and backpressure mechanisms are required to handle these scenarios.
Popular CDC Tools and Technologies
Several tools and technologies have emerged to simplify CDC implementation. Here are some of the most popular ones:
Debezium: An open-source distributed platform for CDC, Debezium connects to databases like MySQL, PostgreSQL, and SQL Server, and streams change events to Apache Kafka. It's widely used for building event-driven architectures.
AWS Database Migration Service (DMS): AWS DMS supports CDC for replicating data between on-premises databases and AWS cloud services. It's a fully managed service that handles the complexities of CDC for you.
Google Cloud Dataflow: Google's stream and batch data processing service can be used to implement CDC pipelines. It integrates with various databases and supports real-time data processing.
Summary
Change Data Capture (CDC) is a powerful technique for tracking and replicating changes in databases in near real-time. It is particularly useful in modern data architectures where data needs to be synchronized across diverse systems such as transactional databases, data warehouses, and search engines. CDC offers several advantages, including reduced load on source systems, near real-time data replication, and support for event-driven architectures. The article explores various CDC mechanisms, including Diff-Based, Timestamp-Based, Trigger-Based, and Log-Based CDC, and provides practical examples of implementing CDC in PostgreSQL and MySQL. While CDC is highly beneficial, it also presents challenges such as performance overhead, data consistency, and handling schema changes. Popular tools like Debezium, AWS DMS, and Google Cloud Dataflow can simplify CDC implementation. By following best practices and choosing the right CDC mechanism, organizations can effectively modernize their data infrastructure and ensure seamless data integration.
References
Reis, J., & Housley, M. (2022). Fundamentals of Data Engineering: Plan and Build Robust Data Systems (1st edition). O'Reilly Media.
Kleppmann, M. (2017). Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
