ljn
Explore how GlassFlow fits into the modern data stack
Written by
Armend Avdijaj
-

This product is no longer available. Check out our latest solution.
You might think about where GlassFlow fits into this modern data stack and how it works alongside other tools. Consider the architecture diagram from the article on emerging architectures for modern data infrastructure, which illustrates the placement of different tools within a unified data infrastructure. GlassFlow is a valuable addition to the modern data stack in the Data Ingestion, Transportation, and Transformation layers by offering serverless, event-driven pipelines that are simple to deploy and manage. In this article, we will explore how GlassFlow fits into the modern data stack and understand the role of GlassFlow in data ingestion, transformation, and streaming.
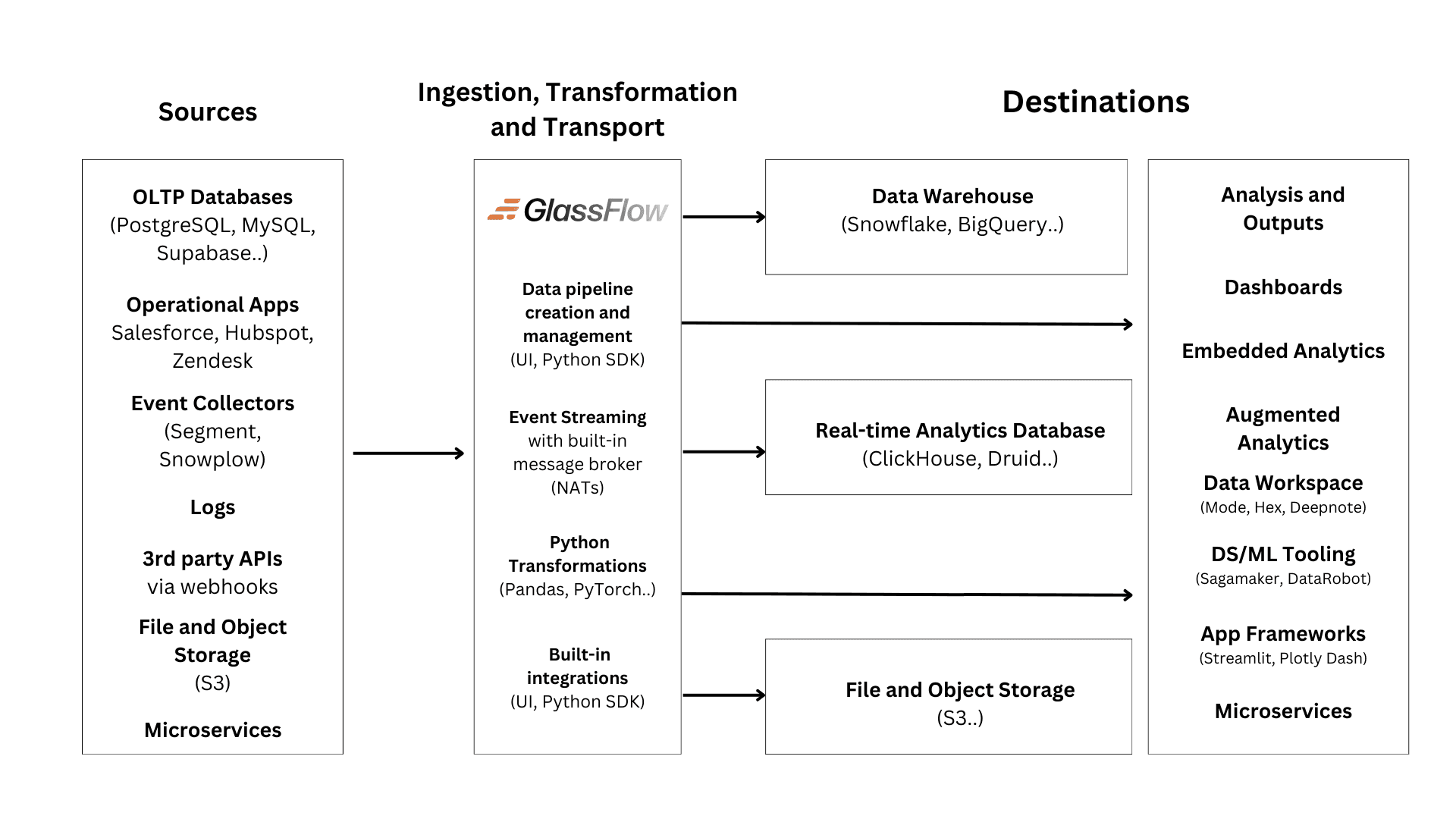
The Limitations of the Modern Data Stack
The "modern data stack" is a term often used to describe the tools and processes commonly adopted in data integration today. It typically includes the following components:
A data warehouse for storing and organizing large amounts of structured data.
A data lake holds large amounts of raw data in its original format, including structured, semi-structured, and unstructured data.
ETL (Extract, Transform, Load) pipelines for moving and transforming data.
A data transformation tool for making the data usable.
A BI (Business Intelligence) tool for extracting insights.
Additional tools for data orchestration, monitoring, and governance.
Many of its foundational concepts, such as data warehouses and ETL pipelines, have existed for over three decades. The modern data stack has excelled in solving the data needs of large enterprises, but it has significant limitations, especially for smaller and growing organizations like startups and non-enterprise users:
Over-Specialized for Enterprises:
The modern data stack is optimized for handling enterprise-level data with complex requirements. Startups and smaller organizations often find themselves paying for features they don't need, resulting in low ROI (Return on investment).Very Expensive:
Setting up a modern data stack requires a substantial investment, which can be out of reach for non-enterprise users. Even maintaining it demands resources that only larger organizations can afford.Complexity of Use:
The tools in the modern data stack are often difficult to use without a dedicated data team. This makes it challenging for smaller teams to adapt and manage effectively.Labor-Intensive ETL Processes:
The backbone of the modern data stack is its ETL pipelines. The "T" (transformation) requires ongoing updates and monitoring as data formats evolve. Each new data source or format demands a new pipeline, which adds to the workload and complexity.Challenges in Business Intelligence: Traditional ETL processes used in data warehouses had long latency and lacked agility. This made it difficult for business intelligence teams to run SQL queries for reporting and creating up-to-date dashboards quickly.
Data Quality Issues: Data Lakes addressed enterprise data warehouse limitations by storing raw data in all formats (unstructured data, such as audio, video, text documents, or social media posts) and using a schema-on-read approach. This made them more suitable for AI/ML, but data often became disorganized in data lakes, leading to problems with data accuracy, reliability, and security.
Why ELT and Zero ETL Are Not Enough
In response to the challenges of ETL, many organizations have turned to ELT (Extract, Load, Transform) or Zero ETL approaches. However, these methods still fall short of modern data integration:
ELT Pipelines:
ELT simplifies the process by deferring transformation to the destination (e.g., the data warehouse). While this reduces some complexity, it still requires heavy computing resources at the destination increases computational costs, and doesn’t address real-time data needs effectively.Zero ETL:
Zero ETL focuses on reducing the need for explicit ETL pipeline creation by integrating directly with source systems. For example, writing one SQL query to request multiple databases like Postgres or MongoDB. Having all the data you will ever need in a single location would make your life easier. However, its adoption is limited by the need for highly specific integrations. It requires more built-in integrations compared to typical ETL pipelines. Also, it is hard to handle diverse data transformation requirements dynamically.
What Defines Modern Data Pipelines
The future of data integration lies beyond traditional ETL, ELT, or Zero ETL. Event-driven pipelines represent a fundamental shift by focusing on real-time, flexible, and scalable solutions.
Event-Driven: Automatically detects changes in data sources and ingests those changes as events.
Continuous Data Flow: Transports event data seamlessly to destinations without interruptions.
Simplified Management: Enables easy creation, monitoring, and updating of data pipelines.
Serverless and Scalable: Uses cloud-based infrastructure to handle growing data demands without manual intervention.
How GlassFlow integrates the modern data pipelines
GlassFlow integrates into the modern data stack by addressing several critical needs:
Simplifying data pipeline creation and management: Easy to build, run, and manage data pipelines without needing extensive infrastructure setup or knowledge.
Improving latency: Enables real-time data processing and fast responses for applications.
Reducing costs: Cloud computing costs can be reduced by running Spark and similar jobs.
Improving data team collaboration: Provides a centralized place where multiple data engineers can work together seamlessly on shared pipelines.
Supporting event-driven architectures: allows pipelines to automatically adjust to schema changes, reducing the manual workload typically associated with ETL or ELT processes.
Bridging the gap with Python for real-time data processing. Python-First for Transformation versus Java. For data engineers and data scientists, building and managing data pipelines in Python is essential because Python is widely used for data manipulation and analysis. It allows them to work with familiar tools and libraries like Pandas, NumPy, and TensorFlow, making it easier to process and transform data. Creating pipelines programmatically in Python allows them to customize workflows for specific needs, such as cleaning messy datasets, enriching data with external APIs, or applying machine learning models.
GlassFlow vs. Other Tools in the Stack
GlassFlow eliminates the need for multiple tools across stages like ingestion, transformation, and streaming. It provides an all-in-one solution for event-driven pipelines.
Category | GlassFlow | Alternatives |
|---|---|---|
Ingestion | Built-in message broker | Kafka, AWS Kinesis |
Transformation | Python-first, serverless | dbt, Airflow |
Streaming | Event-driven pipelines | Kafka, Flink, AWS Kinesis, Pulsar |
Integration | Native connectors for major platforms | AWS Glue, Stitch, Airbyte |
Real-Time Updates | Integrated, no additional setup needed | Confluent, Flink, Upsolver |
Conclusion: Moving Beyond the Modern Data Stack
The modern data stack, while useful for enterprise-level data management, falls short for organizations with smaller teams or more dynamic needs. Event-driven pipelines offer a practical alternative by addressing real-time data challenges and eliminating the complexities of traditional ETL. Read more about how GlassFlow is defining the modern real-time data stack.
References:
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
