ljn
ClickHouse Learnings
Deep dive on raw data ingestions from Kafka to ClickHouse.
Written by
Armend Avdijaj
-

Part 1: How do you usually ingest data from Kafka to ClickHouse?
Before going into the JOINs and duplications in detail, I would like to explain that there are multiple ways to ingest data from your Kafka to ClickHouse. This will help you get an understanding of the basic ingestion concepts and the later explained solutions.
There are multiple ways how to move data from Kafka to ClickHouse. Usually, the way to look at it is by focusing on the desired end result. I recommend thinking through whether you need stream processing before ingestion into ClickHouse or if it is enough to ingest only raw data.
You have the following options to move data from Kafka to ClickHouse:
Kafka Table Engine
ClickPipes
Kafka Connect
Ingesting from Kafka Table Engine to ClickHouse
Using the Kafka Table Engine is very popular among the open-source users of ClickHouse. We recommend using that approach if the following parameters are given:
You need real-time ingestion with minimal transformation
ClickHouse can handle the raw data like it is (no joins, duplications, or transformations needed)
Kafka messages are well structured and are in JSON, Avro, or Protobuf.
If you need more advanced stream processing capability, we don’t recommend using the Kafka Table Engine. Please remember that ClickHouse Cloud (link) does not support it.
In general, it is good to know that the Kafka table engine in ClickHouse lets you read data directly from a Kafka topic, but it doesn’t store the data. It only retrieves it once and moves the consumer offset forward. This means you can’t re-read old messages unless you reset the offset. To keep the data permanently, you need a materialized view, which automatically reads from the Kafka table and inserts the data into a storage table, usually a MergeTree table (see image below - created by ClickHouse)
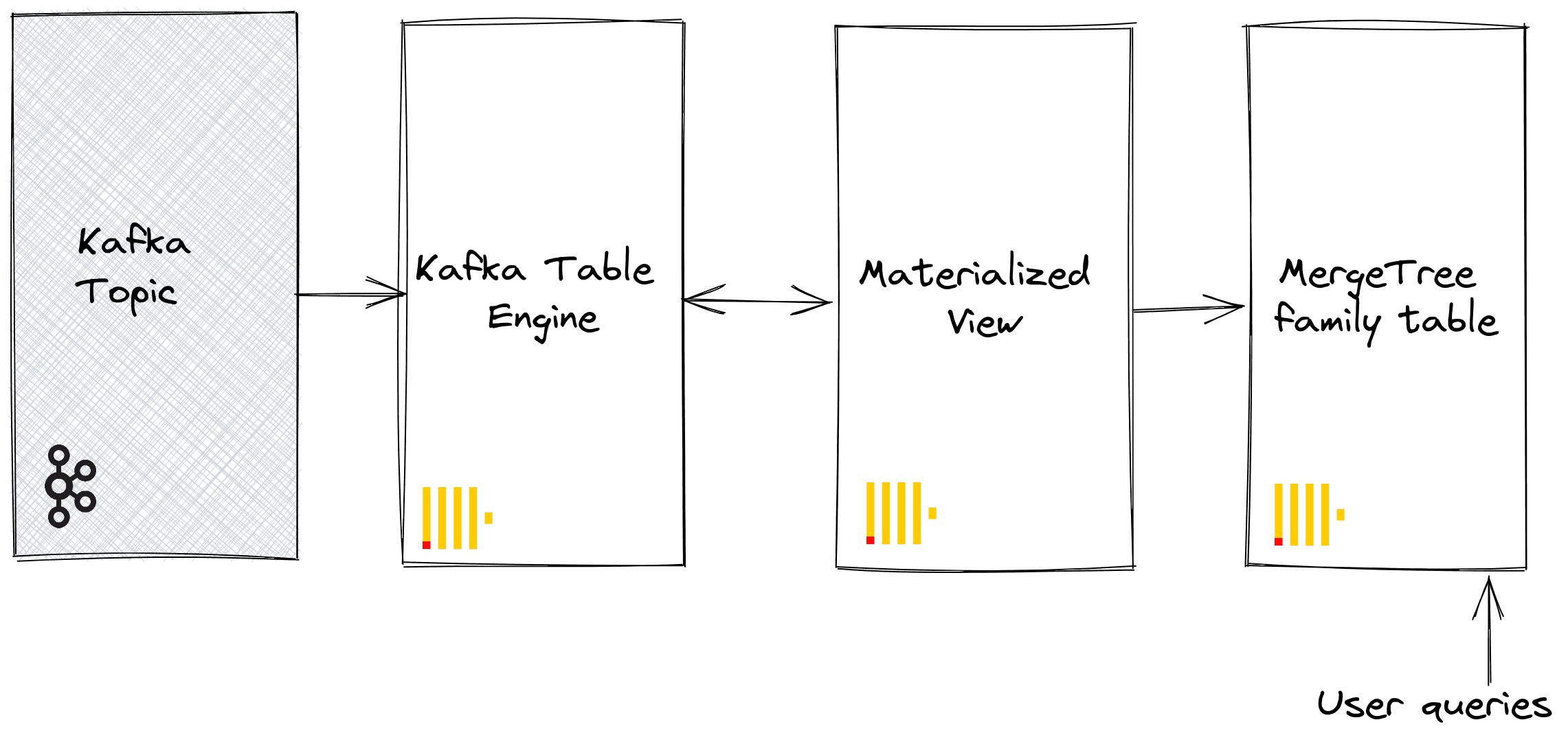
I recommend reading this document on ClickHouse (link) for a step-by-step guide on setting up the Kafka Table Engine.
During the setup, you will understand that you must make several configurations, which could become an issue if you don’t set them properly. This is:
The number of Kafka consumers that will run parallel to tune performance. ClickHouse uses a MergeTree storage engine, where frequent small inserts trigger merges to optimize data storage and query performance. If too many consumers write simultaneously, ClickHouse can spend too much CPU on merges instead of efficiently handling queries. This can lead to increased resource consumption, query slowdowns, and potential instability.
Deduplication: As Kafka doesn't guarantee exactly-once processing you could easily end up with duplications.
Ingesting from Kafka to ClickHouse through ClickPipes
ClickPipes is a streamlined way of connecting to ClickHouse, but remember that they are only available via ClickHouse Cloud. Watch this video from the ClickHouse team (link) to see how to set them up step-by-step.
In general, ClickPipes is a great product. As a managed connector, the maintenance effort is low, the setup is easy, and it is faster than using Kafka Connect. However, ClickPipes has some limitations besides not offering stream processing options.
Potential Duplications:
The current implementation of the Kafka ClickPipe in ClickHouse guarantees at least once (link delivery, meaning messages are ensured to be inserted but might occasionally be duplicated. Achieving exactly-once semantics is complex due to the need for coordinated commits between ClickHouse and Kafka.
Ingesting from Kafka to ClickHouse through Kafka Connect
Kafka Connect is available as an open-source version. The detailed configuration can be found here on the ClickHouse docs.
In general, it makes sense to use Kafka Connect over Table Engines if you have a non-standard Kafka topic (e.g. extremely high/low number of partitions or use Kafka with a non-default retention) or if you want to run some transformation on an event level like manipulating, filtering, or enriching events because Kafka Table Engines are only built for the ingest part of the pipelines.
Below are some configurations you need to take, which could cause bigger issues if set up incorrectly.
Batch Size and Throughput
During configuration, you must set parameters such as batch size, flush size, and the number of tasks. If these values are set too high or too low, they can either overwhelm ClickHouse or lead to resource underutilization. This can also impact latency and throughput. That means you must fine-tune those based on the topic throughput and ClickHouse capacity.
Performance Tuning:
Several parameters can massively impact the ingestion performance. These are message compression, connection timeouts, and retry limits. If you set them wrongly, they can affect the connector's performance and reliability. For example, setting retry limits too low can cause frequent failures during temporary network or ClickHouse issues. Or, if you set the message compression wrongly, it can result in decompression overhead and increase CPU/memory usage, leading to slower ingestion and data losses.
Overview of what ingestion solution to use for moving data without stream processing
Feature | Kafka Table Engine | ClickPipes | Kafka Connect |
|---|---|---|---|
Setup | Simple: Minimal Config | Easy | Complex: Requires connector setup |
Licensing | Open-Source | ClickHouse Cloud | Open-Source |
Flexibility | Limited to only Kafka to ClickHouse | Limited by ClickHouse capabilites | High as it supports multiple sinks, custom connectors and sinking to stream processing solutions |
Each solution is suited to different needs:
If you want a managed service and don’t need stream processing, ClickPipes is the way to go.
If you want to self-host with minimal effort and don’t need stream processing, you can go with Kafka Table Engine.
Kafka Connect is the relevant solution if you want to self-host and plan to use stream processing.
Please remember that all the solutions showcased assume that you work with raw data that don’t need advanced stream processing like JOINs or deduplication.
Try GlassFlow Open Source for ClickHouse on GitHub!
Next part:
Part 2: Why are duplicatios happening and JOINs slowing ClickHouse?
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
