Rethinking the Data Stack for Real-Time Needs
Written by
Bobur Umurzokov
-

This product is no longer available. Check out our latest solution.
Handling real-time data might become significantly expensive, especially for smaller and growing startups and mid-sized companies with limited resources. We are not alone in thinking similarly:
What is an unachievable setup in data infrastructure? A cheap streaming platform that is easy to manage. From the LinkedIn post by Abhishek (ABC) Choudhary.
A modern real-time data stack is designed to balance cost and the growing need for fast data processing challenges. In this article, we will explore how GlassFlow integrates into the modern real-time data stack, what makes it different from other tools, and how it’s helping businesses at the early stage of integrating real-time data.
What Is the Modern Real-Time Data Stack?
Think of the modern real-time data stack as a toolkit for dealing with fast-changing information. You don’t have to wait for batch jobs or long intervals. Instead, it’s about handling data as it’s generated. The modern real-time data stack isn’t just about speed. It’s also about being ready to adapt and innovate. For startups and growing businesses, agility is everything. This means you can focus on launching products, experimenting with data-driven features, and delivering value to customers without being bogged down by infrastructure management. Here, we’ve outlined the key features of the modern real-time data stack.
Key characteristics of the Modern Real-Time Data Stack:
Event-Driven Processing: Reacts to changes in data as they happen (For example, new row is added, updated, and deleted in relational databases).
Continuous Data Flow: Without waiting for batch jobs; the data moves seamlessly from the source (PostgreSQL, MongoDB) to the destination (ClickHouse, Snowflake, S3).
Real-Time Transformation: Data is cleaned, enriched, and filtered as data flows in real-time.
Cloud-native services: Cloud-based infrastructure handles growing data demands without DevOps-heavy setups.
What’s the Difference from the Modern Data Stack?
The modern data stack primarily revolves around batch processing and analytics at scale. Its components include data warehouses, data lakes, ETL pipelines, BI tools, and orchestration frameworks. While the modern data stack is excellent for historical data analysis, this stack is not suitable for real-time needs where data changes require immediate actions. For those of you already familiar with the modern data stack, the biggest difference is the shift from static dashboards to live, dynamic updates—making it perfect for fraud detection, live tracking, real-time AI apps, and personalized recommendations.
Key Players in the Modern Real-Time Data Stack and Their Limitations
When I started exploring real-time data tools, I kept running into the same issues: complexity, steep learning curves, and high costs. Let's have a closer look at the top 3 key players in the modern real-time data stack and understand their limitations.
Kafka
Have you tried setting up Kafka? If yes, you know how hard it is to configure clusters, manage distributed logs, and debug issues.
Complex Setup and Management: To use Kafka, you’ll need to set up a cluster (self-hosted or managed by services like Confluent, Azure, or AWS), stream data with Java-based Kafka Streams, build a compute environment with tools like Spark or Flink, connect to a data store, and manage the entire infrastructure. All this happens before you can even start writing code that adds real value.
Learning Curve: Kafka’s native APIs are Java-based, which can be difficult for data teams who primarily work with Python. While there are Python connectors like Confluent’s Kafka Python library, they lack the maturity and features of the Java API.
Distributed Nature: Debugging distributed Kafka is inherently complex, requiring an understanding of distributed logs, offsets, and consumer/producer configurations.
Scaling and Resource Management: While Kafka can scale, configuring it to scale automatically with data volume increases is challenging. Improper scaling can lead to bottlenecks and performance issues. Kafka is designed for the short-term storage of events. Retaining events for longer periods requires significant disk space and increases costs.
Limited Local Development Support: Kafka's distributed nature makes it difficult for data teams to replicate pipelines locally. This creates barriers when trying to experiment, reproduce, or debug ML models offline.
High Cost of Ownership: Running Kafka clusters, especially at scale, incurs high infrastructure costs, making it expensive for smaller teams or startups.
Spark
Batch-Centric: Spark doesn’t handle real-time data streaming completely. Instead, it breaks live data streams into small batches called Spark RDDs (Resilient Distributed Datasets). Operations like join, map, or reduce are applied to these batches, and the results are processed in batches too. This approach, known as micro-batching, means Spark Streaming offers near-real-time processing but not true real-time.
Resource-Heavy: While working with Spark, memory consumption is very high. It is expensive to keep data in memory. As a result, Spark jobs require significant computing CPU resources, leading to high cloud costs for continuous pipelines.
Scaling Complexity: Dynamically scaling workloads demand advanced configurations and operational oversight. There is no automatic optimization process in Spark. You have to optimize the code or dataset by yourself. A fixed number of partitions is required for parallelization. This is to be fixed and passed manually.
Learning Curve: Spark has many concepts and components to learn, like RDDs, DataFrames, Datasets, SparkSession, SparkContext, transformations, actions, and more. It also requires an understanding of distributed systems and parallel programming, including topics like data partitioning, shuffling, and serialization, making it challenging for beginners.
Debugging Challenges: Spark's architecture and execution model is complex, making it challenging to debug issues and monitor its performance effectively.
Flink
Hard to Learn: Flink is powerful, no doubt, but it’s designed for experienced Java or Scala developers which can slow adoption by new developers.
Heavy Operational Overhead: Managing Flink clusters demands significant DevOps support, from resource allocation to handling job failures.
Debugging Challenges: The asynchronous, distributed nature of streaming data makes troubleshooting pipelines difficult.
Scaling Challenges: While Flink can handle large-scale streaming workloads, scaling it dynamically based on fluctuating data loads requires complex configurations and operational oversight.
Expensive to Run: Maintaining 24/7 Flink clusters for real-time workloads can strain budgets, especially for smaller teams.
Limited Python Support: Flink’s Python support is still evolving, making it less ideal for data teams heavily reliant on Python.
Why Combine Streams and Transformation into One Solution?
Kafka does not natively support complex data transformations(filtering, aggregation, etc.). You often need to pair Kafka with additional tools like Flink or Spark for processing. I should tell you that Kafka and Flink work incredibly well together to boost real-time data pipelines. Kafka can collect and transport huge amounts of information in real-time, acting like a high-speed messenger that moves data reliably data between different systems. Flink specializes in processing that data. It takes the real-time data coming from Kafka, analyzes it, transforms it, or even makes decisions based on it – all while the data is still flowing from Kafka.
However, because of this needed integration, constructing real-time pipelines becomes harder. It requires you to understand your entire architecture, configuring additional data processing infrastructure for Flink using Docker and Kubernetes, along with Kafka Connect for seamless integration with data sources and sinks.
The real value of a data pipeline lies in how the data is transformed and made actionable. By combining streaming and transformation into one solution, teams can:
Simplify Management: Fewer tools to set up and maintain.
Reduce Costs: Lower infrastructure overhead.
Focus on Value Creation: Teams can go live with real-time pipelines in days rather than months. Instead of wrestling with complex configurations and integrations, data teams can spend more time on data enrichment, anomaly detection, and ML-driven transformations, directly impacting business outcomes.
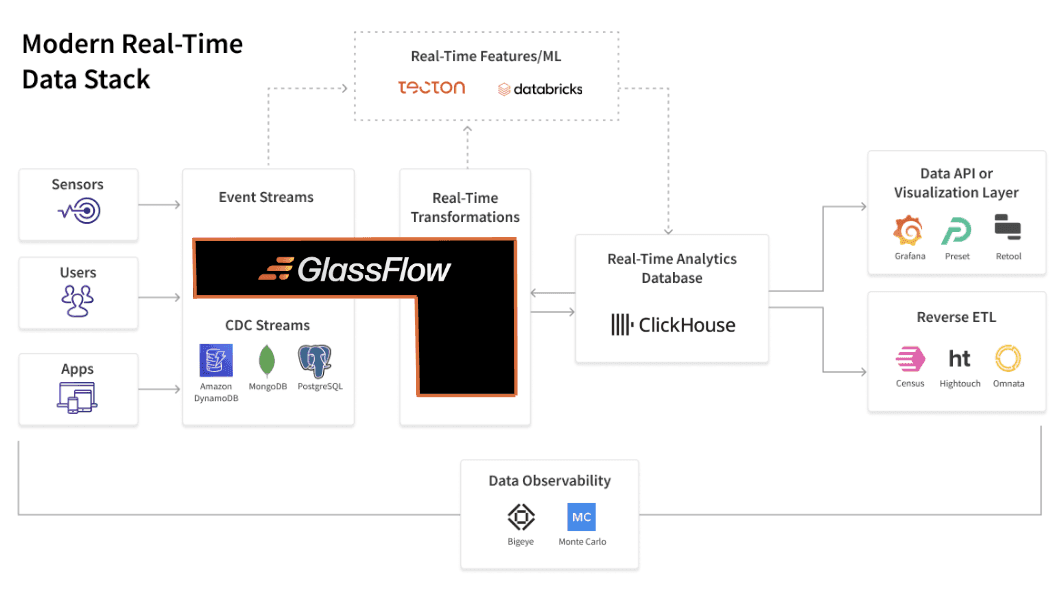
Where GlassFlow Fits Modern Real-Time Data Stack
Referencing the provided diagram, GlassFlow plays a central role in the modern real-time data stack by simplifying the ingestion, transformation, and delivery of data:
Event Streams and CDC Streams: GlassFlow integrates with sources like Amazon DynamoDB, MongoDB, and PostgreSQL, capturing changes as they happen through Change Data Capture (CDC) techniques.
Real-Time Transformations: GlassFlow adds value by enabling Python-based transformations in real-time.
Real-Time Analytics Databases: GlassFlow works seamlessly with tools like ClickHouse, ensuring that the analytics databases always receive fresh, enriched data.
Data API or Visualization Layers: GlassFlow pipelines connect to visualization tools like Grafana and Retool, enabling teams to create dynamic dashboards and real-time insights.
Reverse ETL: Data processed in GlassFlow can be sent back to operational systems through reverse ETL tools like Census or Hightouch, enabling actions based on the latest data.
What Makes GlassFlow Shine in the Real-Time Data Stack?
Setting up a modern real-time data stack requires a substantial investment, which can be out of reach for non-enterprise users. Even maintaining it demands resources that only larger organizations can afford. GlassFlow enables startups to deploy real-time pipelines in days instead of months. GlassFlow integrates data movement, transformation, and enrichment into a single platform, reducing complexity.
Python-First Design: Built for data engineers familiar with Python, reducing the learning curve and enabling faster adoption.
Serverless Simplicity: No infrastructure management is required; GlassFlow scales automatically to handle increasing loads.
Built-In Message Broker: Unlike Kafka, GlassFlow’s broker is pre-configured and scales seamlessly, reducing setup time.
Simplified data pipeline creation and management: From ingesting data to delivering it to analytics tools, GlassFlow eliminates the need for using multiple tools (e.g., Kafka for streaming, Flink or Spark for transformations). GlassFlow provides a centralized place where multiple data engineers can work together seamlessly on shared pipelines. This helps to improve data team collaboration**.**
Use Cases of GlassFlow in the Modern Real-Time Data Stack
Real-Time Logistics Tracking
A logistics company needs to track and optimize routes based on real-time updates from GPS trackers on their fleet. GlassFlow processes GPS updates in real-time, applies route optimization algorithms, and sends instant instructions to drivers or dashboards. Companies save on fuel costs, improve delivery times, and ensure better customer satisfaction with accurate ETAs and efficient routes.
Automated Pipeline Creation for SaaS Platforms
A SaaS platform offering analytics to multiple clients wants to create and manage unique data pipelines for each new customer without manual intervention. GlassFlow enables automated pipeline creation using Python scripts. When a new customer signs up, the system triggers a Python function that dynamically generates a customized data pipeline tailored to the customer’s needs—handling ingestion, transformation, and delivery automatically. This allows data teams to focus on enhancing their product rather than managing repetitive backend tasks.
Customer Data Personalization
Real-time personalization leads to higher conversion rates and improved user satisfaction, giving retailers a competitive edge in a crowded market. GlassFlow ingests real-time clickstream data, enriches it with customer profiles, and applies machine learning models for predictions. This data is then sent to the app to deliver customized offers within seconds.
Branching AI Pipelines for Complex Parsing
AI-driven applications often require complex parsing workflows where data needs to be processed differently depending on its type or structure. Consider an AI document parsing solution for a legal tech platform.
GlassFlow enables branching the pipeline into three paths:
Extract text from scanned PDFs using OCR.
Identify legal clauses using an NLP model for structured text.
Process images or diagrams within the documents using a vision model.
Each branch processes the respective type of content and merges the results back into a unified dataset, ready for downstream tasks like summarization or classification in real time.
Conclusion
As you can see in each use case, GlassFlow combines ingestion, transformation, and delivery in a serverless, Python-first environment. GlassFlow is at the forefront of this transformation, providing a unified solution that simplifies real-time data pipelines. In 2024, the shift towards real-time has been faster. According to a Gartner report, over 70% of organizations now prioritize real-time analytics for their decision-making processes, compared to just 55% in 2022. Furthermore, the global real-time data processing market is projected to grow from $18 billion in 2023 to $28 billion by 2026, reflecting the rising demand for instant insights and responsiveness.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
