Clickhouse and the limitations when it comes to JOINS
Written by
Armend Avdijaj

Clickhouse and Its Limitations with JOINS
This article explains how JOINs are implemented in ClickHouse, what their limitations are, and how to overcome them at scale.
Introduction to Clickhouse
Clickhouse has rapidly become the go to option for analytical workloads, but like any tool, it comes with its own set of trade-offs — especially when handling JOIN operations.
Clickhouse is a column-oriented database system designed specifically for analytical workloads (also known as OLAP). It excels in scenarios like real-time log analysis, time-series data processing, and large-scale event tracking due to its ability to process billions of rows per second. One notable aspect of Clickhouse is that it offers both cloud and open-source versions, providing flexibility for testing and deploying it based on application needs. The open-source version, released under the Apache 2.0 license, allows users to self-host, and customize the system to meet specific requirements. Meanwhile, the managed cloud service reduces operational overhead, making Clickhouse accessible even for teams without dedicated infrastructure engineers.
What is a Column-Oriented Database?
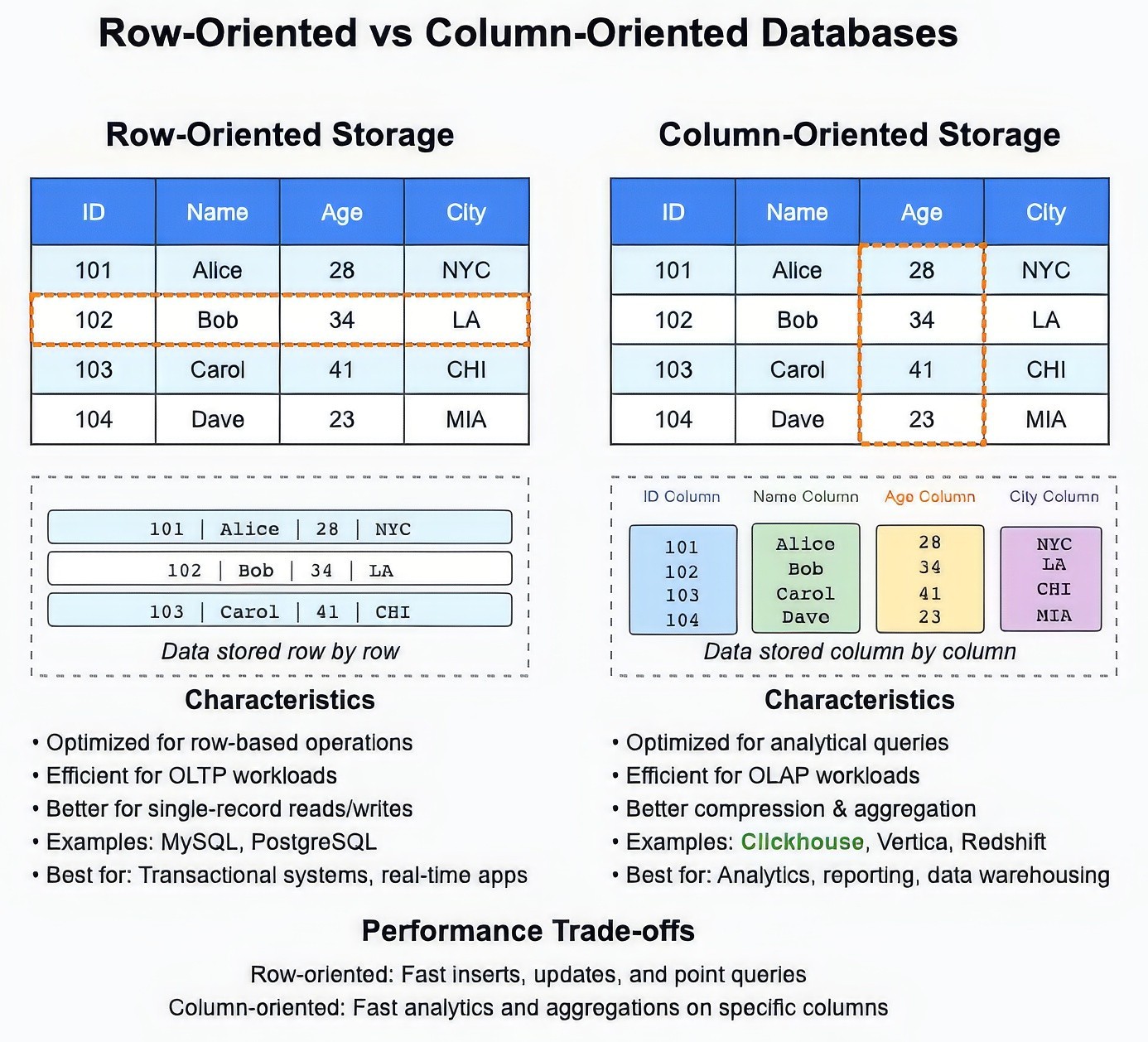
Figure 1: Row vs Column Oriented Databases – A Visual Overview
To understand it’s strengths and limitations, it’s crucial to grasp the concept of column-oriented storage. Traditional DBMS systems like MySQL are row-oriented, which meant that data is stored sequentially by rows. While this structure resulted in really good performance for inserting and deleting records, there are major bottlenecks in querying, filtering, and aggregating data (i.e., Analytical queries). The reason for this bottleneck is that even if you need data from one or two columns, the system must read entire rows from disk, wasting valuable I/O resources.
Column-oriented databases solve this problem by storing data sequentially by columns instead of rows. This methodology has a lot of advantages:
Faster Queries: Only the relevant columns are read during a query, reducing I/O operations, and speeding up results.
Efficient Storage: Storing similar data types together allows for better compression, reducing storage costs.
Accelerated Aggregations: Operations like SUM, AVG, and COUNT can be performed faster because the database can scan entire columns without row-wise access.
Since data is stored in columns, the database can quickly scan and process only the necessary data without loading entire rows. This makes analytical queries much faster, especially for large datasets, because modern processors can handle batches of column values much more efficiently. These advantages make Clickhouse incredibly powerful for analytical workloads, where aggregations, filtering, and complex queries are the primary requirements. However, this results in a few tradeoffs as well. We will specifically focus on Join related limitations for Clickhouse in this blog.
Join Limitations in Clickhouse
To get a better idea on the drawbacks for JOINs for Clickhouse, let’s explore what are the features that Clickhouse currently supports when it comes to JOINs.
Clickhouse JOINS: The Present Scenario
Clickhouse currently has Full JOIN support, meaning that it’s supports all the major JOIN types:
INNER JOIN
OUTER JOIN
CROSS JOIN
SEMI JOIN
ANTI JOIN
ANY JOIN
ASOF JOIN
In the interest of time, I have created a simple visual representation of each JOIN type so that you can know the distinction and characteristics of each.
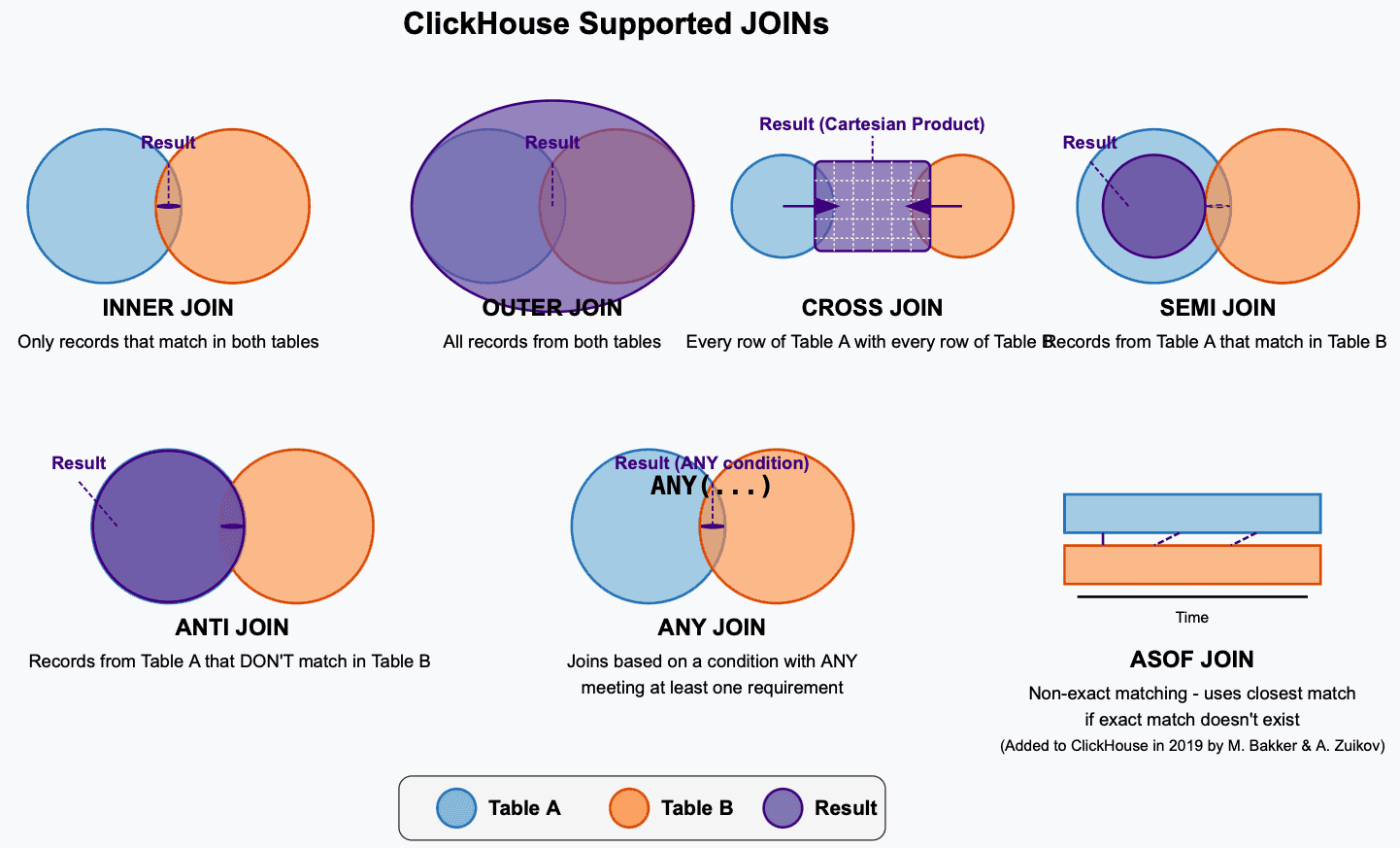
Figure 2: Join Types on Clickhouse
However, as Clickhouse is an analytical workload focused database, it’s designed in such a way that it always prompts the user to adopt a flat table (denormalized) structure, which involves merging related data into a single table for faster querying. However, this results in various disadvantages like:
Additional ETL Pipeline for Data Denormalization.
Reduced Data Redundancy.
Increased Storage Requirements.
Now, let’s explore the most important question for this blog: “Why are JOINs limited in Clickhouse?”. There are several reasons for this, the first being that almost all OLAP Database solutions do not focus on JOINs as these operations are generally expensive and time consuming and hence, not preferred for analytical querying.
Why are JOINs so limited in Clickhouse?
As discussed above, the short answer for this is: “Joins aren’t a high priority operation for analytical workloads”. However, in real-time data pipelines, multiple joins may be required with complex queries for huge tables for certain use cases. For instance, what if you want to query a table which records all interactions of users for a website. That would be millions and billions of records that you would have to join with some existing data. That is where Clickhouse’s offering falls short.
Here are the primary limitations that Clickhouse has for these kinds of scenarios:
Rule-Based Query Planning: This is a crucial step for executing any query in a database. This involves converting the actual SQL query into an actual physical operational plan (where optimization is key) which is then executed to get the results. This is a very advanced topic and hence, we won’t be going into the details for this.
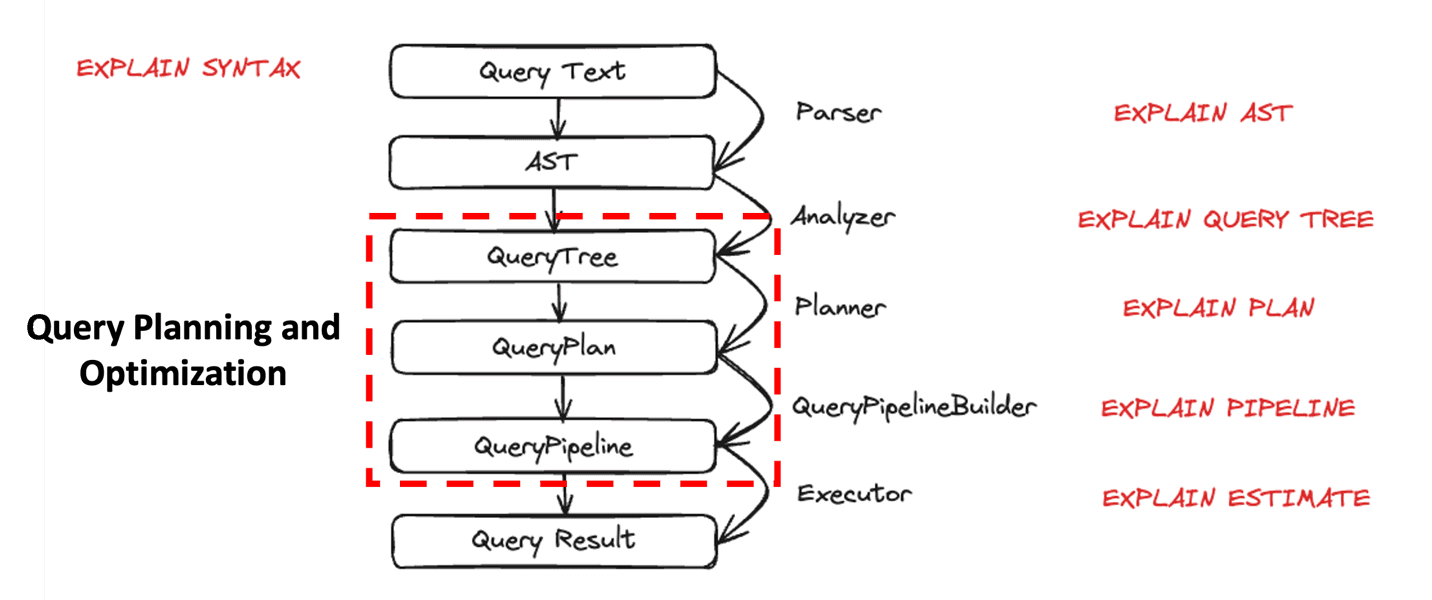
Figure 3: Clickhouse Query Execution Steps (Source)
Let’s consider a scenario for better understanding. Imagine you run a large e-commerce store, and you want to analyze millions of sales records to find the top products sold in each region. Let’s say this data is split across multiple tables — one for sales, another for product details, and a third for customer information. In a typical database, a well-optimized query planner would carefully decide the best way to join these tables.
However, ClickHouse's rule-based planner follows a fixed set of rules to decide how to execute the query, rather than dynamically adapting to the data. For smaller tables, this might not be a big issue. But when joining large tables with millions (or billions) of rows, an inefficient join plan can drastically slow performance or even cause the query to fail.
The main drawbacks for the Planner that Clickhouse employs are:
It is rule-based and so can create inefficient plans for complex queries.
It looks at limited metrics for the actual data, which can hurt the performance very severely for operations like joins where a table is too big. It can also result in failures.
Lack of advanced optimization implementations.
Since JOINs are inherently expensive operations, the lack of advanced query planning makes them even slower in Clickhouse. Without a sophisticated planner that can reorder tables, choosing the best join algorithm, or split queries into smaller, more manageable parts, complex JOINs on large datasets can quickly become a bottleneck.
Limited Support for Distributed Join Algorithms: In scenarios where the data is too large to fit in memory on a single node — or even a small cluster of nodes — Clickhouse struggles because it lacks dedicated distributed JOIN algorithms. This is a natural limitation given its architecture, which is optimized for speed and low-latency queries, but it can cause issues for complex analytical tasks involving massive tables.
Clickhouse currently supports six join algorithms:
Direct Join: Fastest when the right-hand table is small and can fit in memory, acting like a key-value lookup.
Hash Join: Builds an in-memory hash table from the right-hand table for fast lookups.
Parallel Hash Join: Same as hash join but parallelized to speed up processing for larger tables (at the cost of more memory).
Grace Hash Join: Handles large tables by spilling data to disk, avoiding the need for pre-sorting.
Full Sorting Merge Join: Sorts both tables and merges them, useful for pre-sorted data, but adds sorting overhead.
Partial Merge Join: Minimizes memory usage by sorting the right table and processing the left table in smaller chunks.
While these algorithms offer flexibility, none of them truly solve the issue for massive, distributed datasets. Let’s break this down:
No Data Shuffling: In distributed databases, data shuffling allows worker nodes to share relevant data chunks instead of each node processing the entire table (refer to Figure 4). Clickhouse lacks this feature, so each node processes its part of the data independently and then combines the results. This works fine for simple queries but becomes painfully slow (or even fails) for complex JOINs involving large tables.
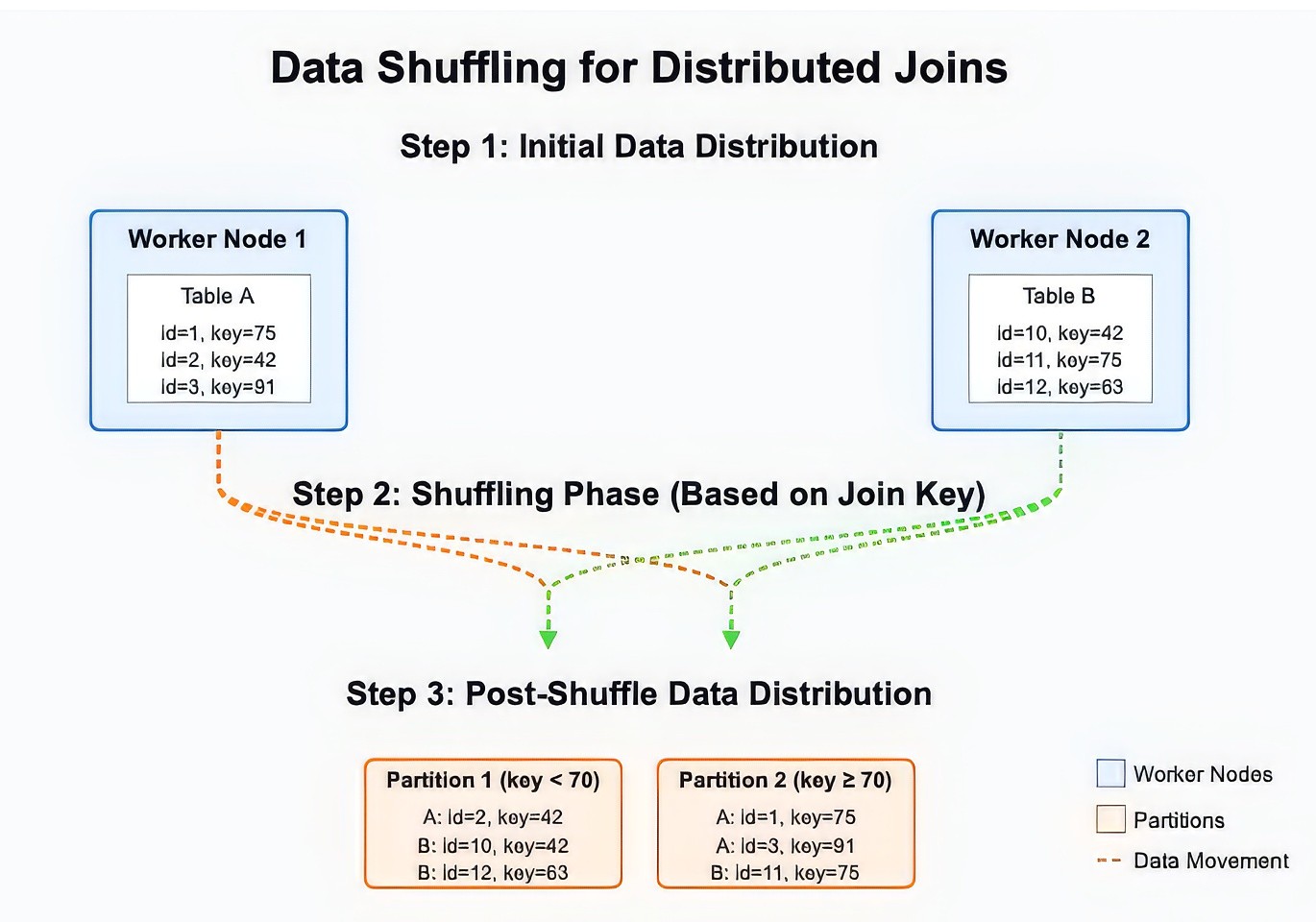
Figure 4: What is Data Shuffling?
Multiple JOINs = Multiple Rounds of Data Exchange: If your query involves multiple JOINs, Clickhouse repeats the process of gathering and merging results for each join. Without distributed join optimization, this can create delays that keep on adding exponentially as the data grows larger.
Imagine you have a billion-row table of website user interactions, and you want to join it with another billion-row table of customer data. In Clickhouse, each node processes its share of the data, and then the results are merged — which can be incredibly slow or cause out-of-memory failures in contrast to distributed systems, which have data shuffle capabilities.
Clickhouse does offer configurable settings like max_rows_in_join and max_bytes_in_join to prevent outright memory failures, but these are more guardrails than true solutions. It’s important to note that not supporting data shuffling is a design choice to make single-table queries lightning-fast. However, for use cases that require complex joins across massive datasets, this trade-off becomes a significant hurdle.
Preference for Data Denormalization: One of the reasons Clickhouse can deliver lightning-fast query speeds is because it works best with denormalized data— meaning all the information is stored in a single, large, flat table instead of being spread across multiple related tables. This reduces the need for JOINs, which are inherently slower operations, but it comes with trade-offs.
In a normalized database (like MySQL), you might store customer data in one table and order history in another. To get a complete view of a customer’s transactions, you would use a JOIN to combine the tables. In Clickhouse, the recommended approach is to pre-merge this data into a single table through your ETL (Extract, Transform, Load) pipeline — so your queries can be blazing fast without needing runtime joins.
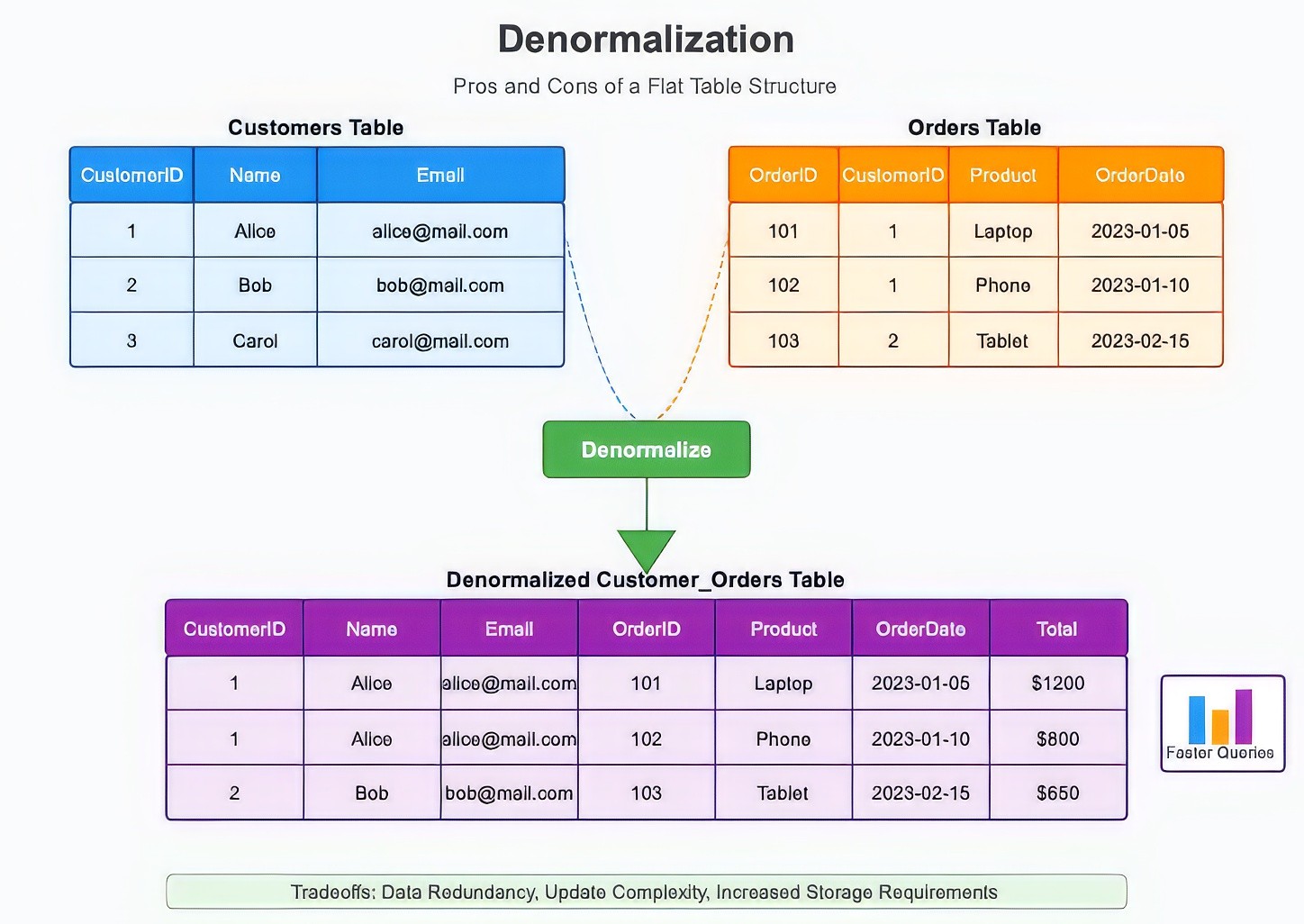
Figure 5: Data Denormalization and it’s considerations
Based on the above visualization of denormalization, here are the key advantages and disadvantages of using the data denormalization design for your use cases:
Advantages
Faster Queries: No need for costly JOIN operations since all data is already in one place.
Simplified Query Execution: Queries become straightforward, reducing the chances of performance hits.
Disadvantages
More Storage Needed: Storing duplicate data across rows (like customer details) can drastically increase storage size.
Complex Queries: If you need to update a single piece of information (like a customer’s email), you must update every row where that data appears, which can be computationally expensive.
Additional Steps in ETL Pipelines: Transforming and flattening your data requires more upfront effort and adds complexity to your data ingestion process.
Since Clickhouse is optimized for this data format, JOINs are treated more like a fallback option rather than a core feature. The system encourages you to reshape your data outside the database (during ingestion) instead of relying on complex JOINs at query time. This makes Clickhouse incredibly fast for analytical queries but limits its flexibility for ad hoc exploratory queries that require heavy joins across large tables.
For instance, imagine you’re running a subscription service and want to analyze user activity. In a normalized setup, you might have separate tables for users, subscriptions, and payment records. In Clickhouse, the ideal approach would be to combine all this data into a single "user_activity" table during ingestion, so your analytics queries run in milliseconds. But if your business logic changes, and you suddenly need a new join that wasn't part of the original flattened structure, you might end up reworking your entire ETL pipeline just to make the system operational and usable.
Conclusion
In summary, while Clickhouse is a very capable product for analytical query processing, users have to keep in mind the architecture and assess if it’s suitable for their use case. In fact, Clickhouse themselves recommend to keep joins at a minimum to get the most out of their platform.
That being said, there are several solutions that will allow us to solve these problems, especially when it comes to complex joins. We will be discussing the possible solutions for this drawback in the next article:
Read now: How to Solve JOIN Limitations in ClickHouse
If you are looking for an easy and open-source solution to solve duplicates and JOINs at ClickHouse, check out what we build with GlassFlow:
Try GlassFlow Open Source on GitHub!
Did you like this article? Share it!
You might also like



Transformed Kafka data for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
