Python Streaming Database vs. Stream Processing Frameworks
Written by
Bobur Umurzokov
-

To fully leverage the data is the new oil concept, companies require a special database designed to manage vast amounts of data instantly. This need has led to different database forms, including NoSQL databases, vector databases, time-series databases, graph databases, in-memory databases, and in-memory data grids. Recent years have seen the rise of cloud-based streaming databases such as RisingWave, Materialize, DeltaStream, and TimePlus. While they each have distinct commercial and technical approaches, their overarching goal remains consistent: to offer users cloud-based streaming database services.
However, a streaming database is an independent system that is completely decoupled from other data storage such as general-purpose databases and data lakes. As a result, data must be synchronized, streamed, and handled across various systems. In this article, we'll examine the differences between streaming databases and other stream-processing options. We'll also explore the reasons behind the existence of Python libraries for stream processing. Ultimately, this article aims to guide you as a developer, data engineer, or data scientist in your research when it comes to making the right choice.
How are streaming databases different?
Different from traditional databases
Streaming databases are also the extension of traditional SQL databases such as PostgreSQL or MySQL. Like a traditional SQL database, the streaming database encompasses SQL syntax, a parser, and an execution mechanism. Querying and manipulating data can be achieved through SQL declarative language which gives developers or data engineers the flexibility to query stream data easily with typical SQL statements such as SELECT, FROM, WHERE, or JOIN. However, streaming databases differ from traditional databases and there are notable distinctions between in-memory continuous queries in stream processing and traditional database queries. Streaming databases consume streaming data from one or more data sources, allow querying of this data, perform incremental computations when new data comes in, and update results dynamically.
Streaming databases handle continuous queries on endless data flows.
Different from conventional analytic database
They differ from conventional analytic databases like Snowflake, Redshift, BigQuery, and Oracle in several ways. Conventional databases are batch-oriented, loading data in defined windows like hourly, daily, weekly, and so on. While loading data, conventional databases lock the tables, making the newly loaded data unavailable until the batch load is fully completed. Streaming databases continuously receive new data and you can see data updated instantly. Materialized views are one of the foundational concepts in streaming databases that represent the result of continuous queries that are updated incrementally as the input data arrives. These materialized views are then available to query through SQL.
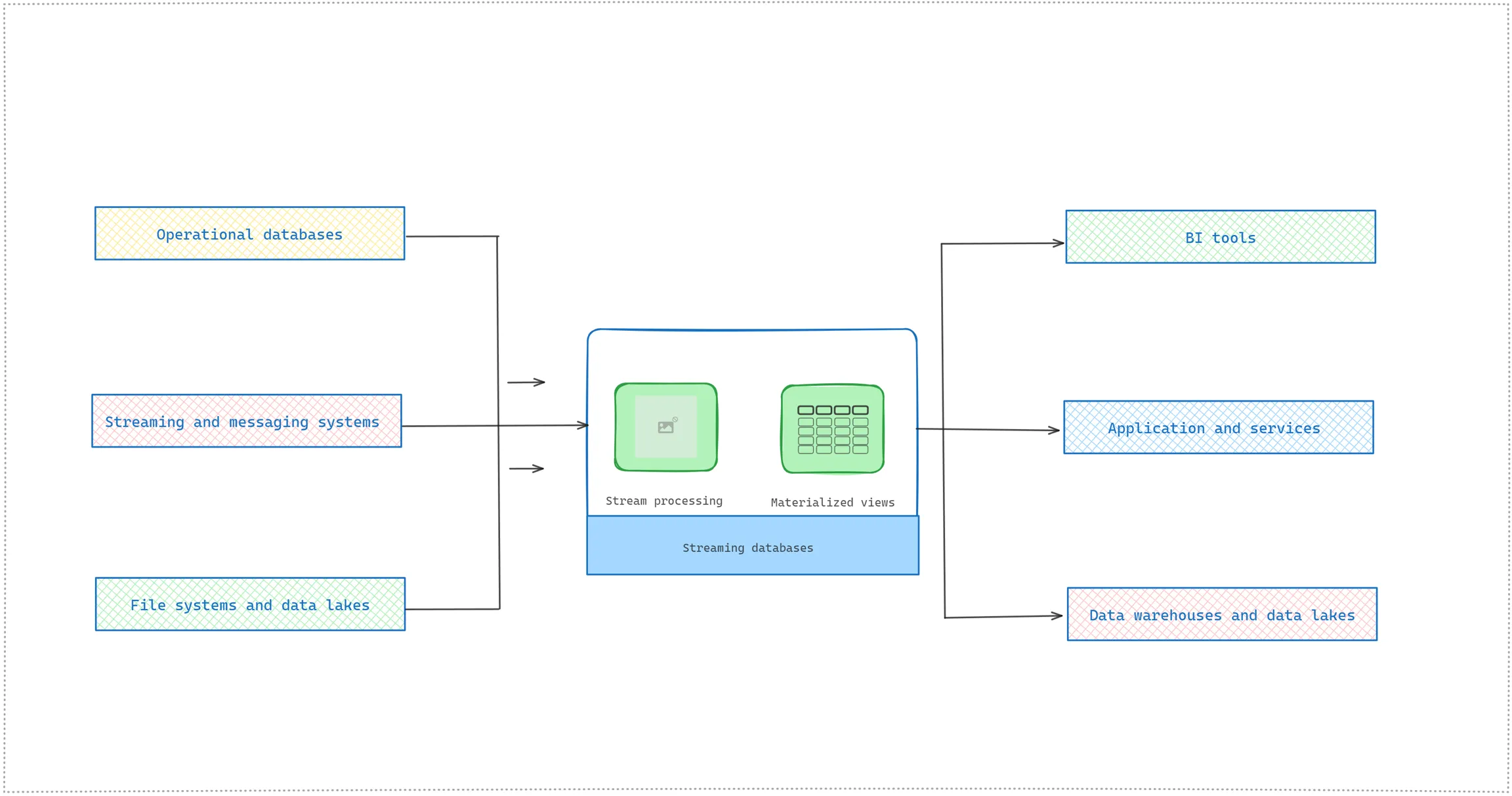
Different from OLAP databases
Online analytical processing (OLAP) databases like Apache Druid, Apache Pinot, and ClickHouse shine in addressing user-initiated analytical queries. You might write a query to analyze historical data to "find the most-clicked products over the past month" efficiently using OLAP databases. When contrasting with streaming databases, they may not be optimized for incremental computation, leading to challenges in maintaining the freshness of results. The query in the streaming database focuses on recent data, making it suitable for continuous monitoring. Using streaming databases, you can run queries like "finding the top 10 sold products" where the "top 10 product list" might change in real-time.
Different from stream processing engines
Other stream processing engines (such as Flink and Spark Streaming) provide SQL interfaces too, but the key difference is a streaming database has its own storage. Stream processing engines require a dedicated database to store input and output data. On the other hand, streaming databases utilize cloud-native storage to maintain materialized views and states, allowing data replication and independent storage scaling.
Different from stream-processing platforms
Stream-processing platforms such as Apache Kafka, Apache Pulsar, or Redpanda are specifically engineered to foster event-driven communication in a distributed system and they can be a great choice for developing loosely coupled applications. Stream processing platforms analyze data in motion, offering near-zero latency advantages. For example, consider an alert system for monitoring factory equipment. If a machine's temperature exceeds a certain threshold, a streaming platform can instantly trigger an alert and engineers do timely maintenance.
Now imagine predicting when machinery is likely to fail and then alerting. Such predictions may require historical data on equipment performance, which must be stored for analysis. However, as queries become more complex, involving historical context, it often necessitates data persistence. In this case, a Streaming database can be used to make real-time decisions within context, such as predicting machine failures.
When to use a streaming database?
If you centralize real-time data storage, making it easier to access and analyze data across multiple projects.
If you develop materialized views that are incrementally updated and directly serve them to user-facing dashboards and applications for real-time analytics purposes.
If you are developing event-driven applications where you utilize two distinct data stores: one as the primary data source and the other for streaming data.
Do we really need a specialized streaming database?
Streaming databases are great for serving incrementally updated materialized views directly to end user-facing dashboards and applications. Streaming databases may not be the right tool for building real-time streaming pipelines where the output of one stage in the pipeline is input to another or there are complex event processing rules in the pipeline where you need to implement complex business logic. For example, there might be a complex event processing scenario even in a typical inventory management. When inventory levels for a high-demand product drop below a certain threshold, the system should trigger an automatic reorder by requesting external APIs. Additionally, if multiple items are frequently purchased together, the system needs to identify these patterns, allowing for strategic product placement in the store. As you can not write every single logic using SQL, you need to implement event processing functionality in the application code.
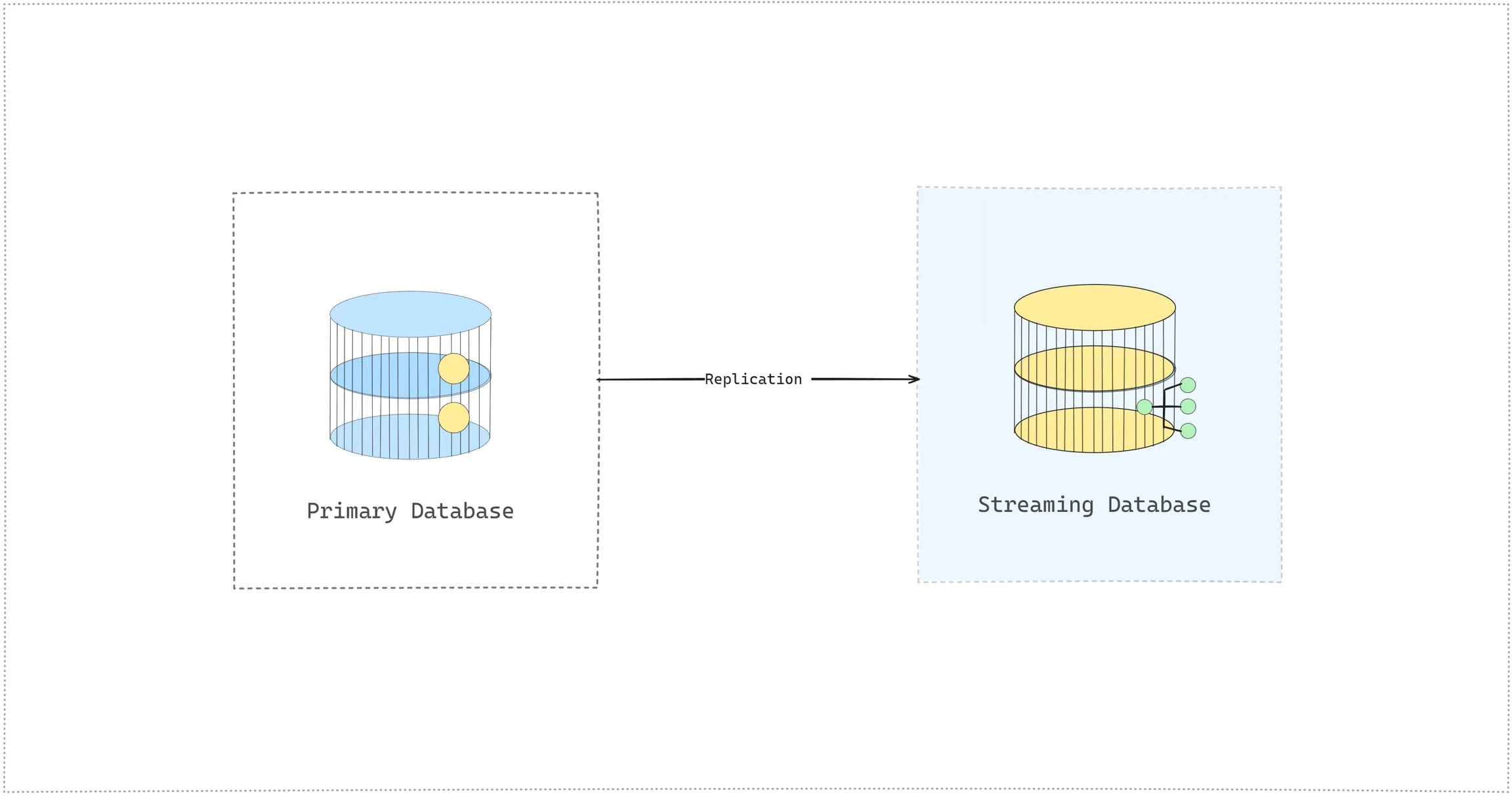
Using a separate streaming database tends to introduce recurring challenges we frequently encounter and address when working with distributed systems. The challenges include redundant data, excessive data movement between primary and streaming databases, issues with data synchronization, handling large volumes of data requires robust infrastructure, limited query language power, programmability, and extensibility.
Stream processing frameworks in Python
We understood how streaming databases differ from traditional databases, stream processing engines, conventional analytics databases, or OLAP databases. Now let’s focus on when and why we can use stream data processing frameworks for Python as an alternative to streaming databases. Python is the go-to language for data science and machine learning. There are some stream-processing libraries (Kafka, Flink) and frameworks in Python (native Python: GlassFlow). Frameworks have been developed to cope with the challenges Python Engineers face with Apache Kafka or Flink since both do not natively support Python.
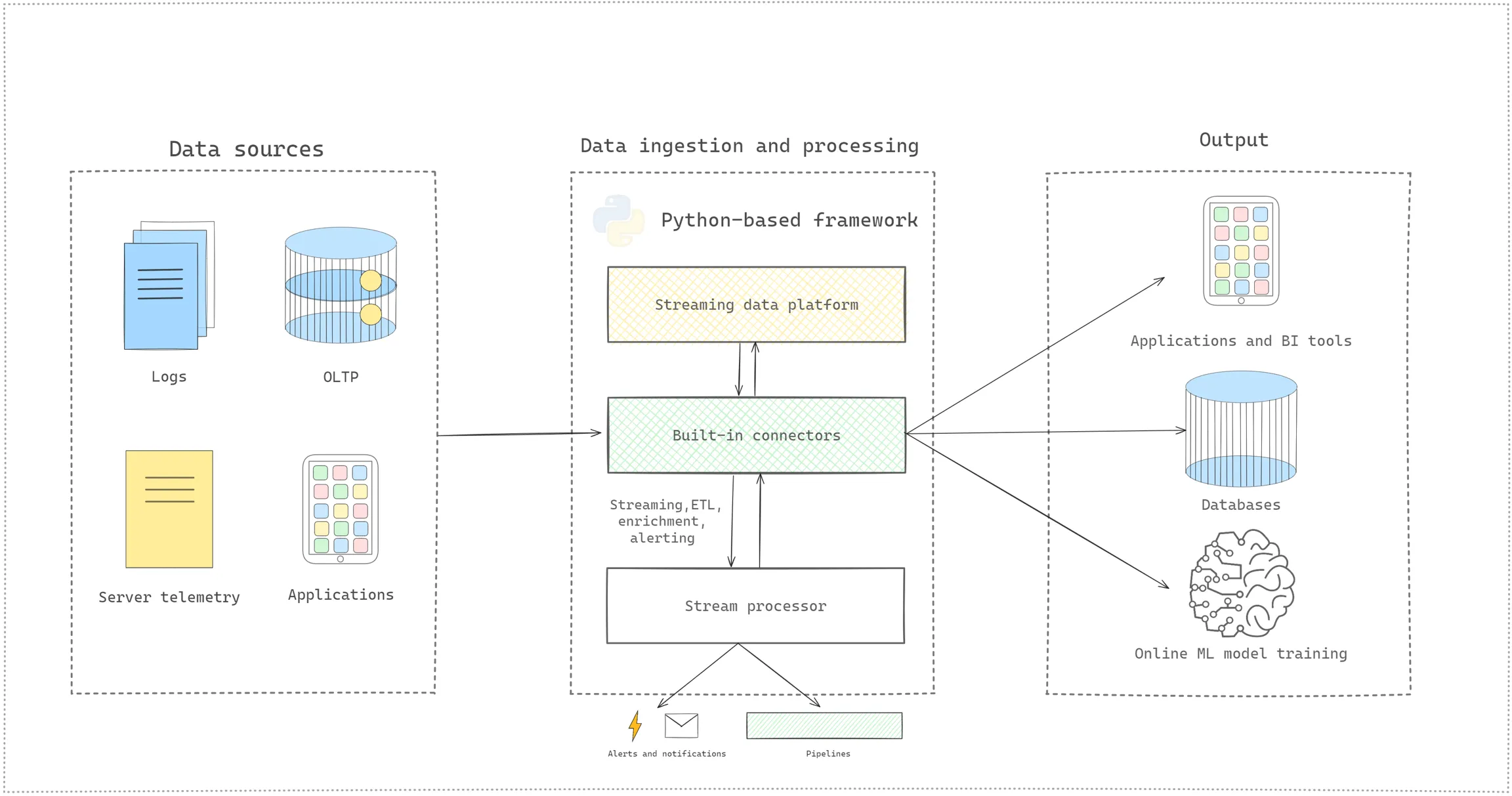
Why use Python for data streaming?
First of all, Python frameworks can be used out-of-the-box with any existing Python library (like Pandas, NumPy, Scikit Learn, Flask, TensorFlow, etc.) to connect to hundreds of data sources and use the entire ecosystem of data processing libraries. They allow Python developers and data engineers to build new data pipelines or modernize existing ones without overwriting the code for batch and stream processing workflow.
As you can see in the diagram above, a Python-based framework unifies the streaming data platform and stream processor components in the streaming data pipeline architecture. You can connect directly to any data source (using built-in connectors) within your application code without knowing how Kafka or other message brokers work and focus on only business logic.
Much easier to get started, because you just need to install a Python library without a complex initial setup like creating computing clusters or running JVM in a Kafka case. For example, topics are the organizational objects in Kafka that hold data events, and these topics are stored in clusters where the user has to provision clusters along with specifying the amount of resources this cluster will have before starting to work with topics.
They manage data in the application layer and your original data stays where it is. This way data consistency is no longer an issue as it was with streaming databases. You can use Change Data Capture (CDC) services like Debezium by directly connecting to your primary database, doing computational work, and saving the result back or sending real-time data to output streams.
They do real-time incremental in-memory transformation of complex event streams including stateful operations like joins, transformation, windowing, and aggregations.
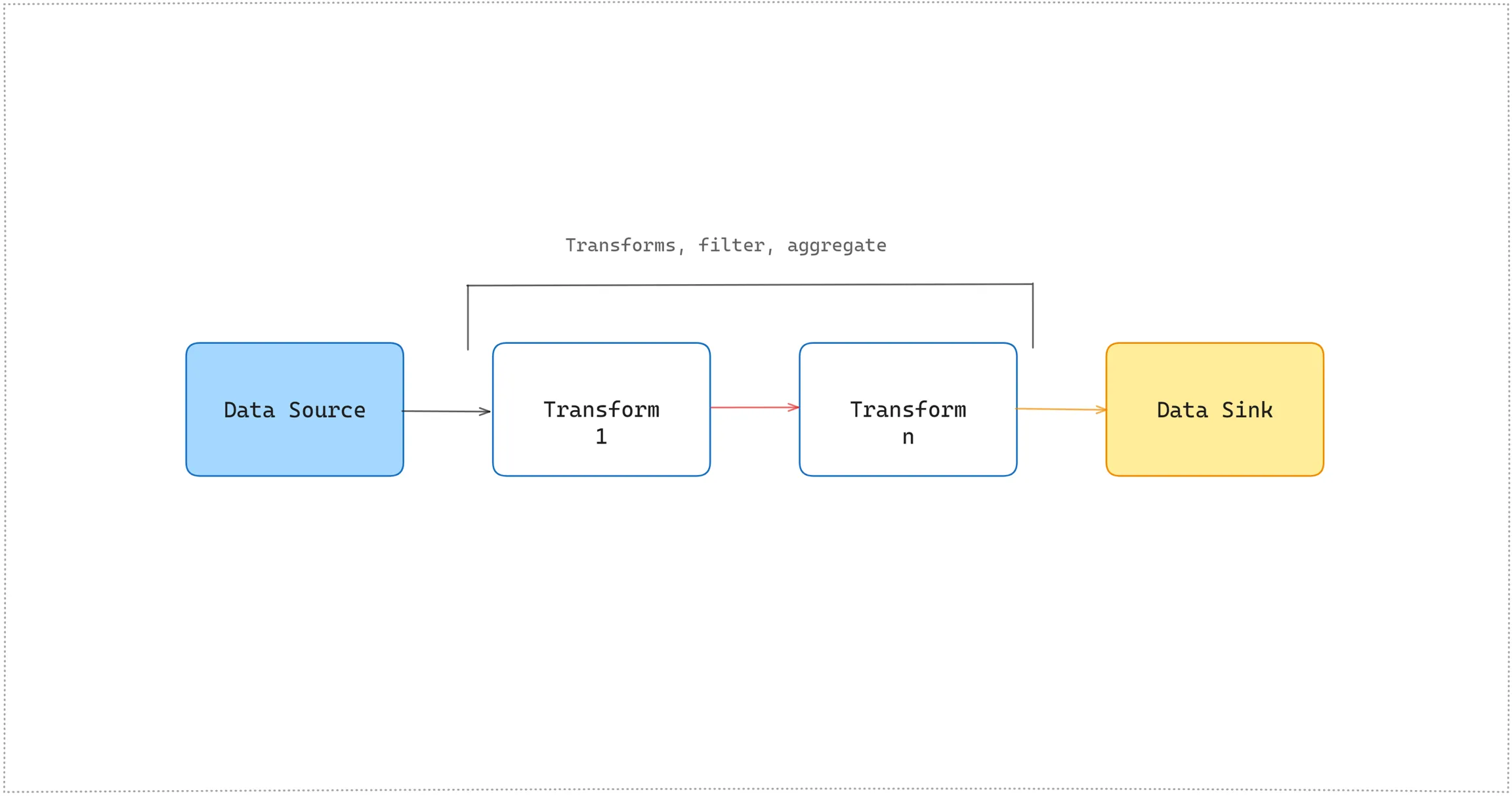
They make it easy to launch multiple case-by-case data science projects and run your local code right from Jupyter Notebook.
Some offer serverless platforms meaning resource scaling and operations are completely taken care of in your environment or any public cloud like AWS, Azure, or Google. You only focus on building your streaming applications and pipelines.
When to use Python frameworks?
Python frameworks can be effectively utilized for building real-time data processing pipelines in various scenarios:
If you have existing/planning to use Python programming language as a main stack for development, data engineering, and machine learning work.
If you want to perform low-latency serverless data streaming with Python.
If you are facing performance issues with an Apache Kafka/Flink/Spark streaming system.
If you have issues with data synchronization in a distributed system like microservices.
If you want to use the same data pipeline for batch and stream processing.
If you need to efficiently do stateful operations such as joins, transformation, windowing, and aggregations.
If you need to create custom data processing pipelines, where you run custom functions to fetch, transform, and call other real-time services.
Conclusion
We went through key considerations for choosing a streaming database or Python-based stream processing framework. Streaming databases are the go-to choice when centralizing real-time data storage. They excel in scenarios where materialized views are incrementally updated and directly served to user-facing dashboards and applications for real-time analytics. On the other hand, Python frameworks are suitable for various scenarios, including Python-centric data streaming pipeline development within the application layer, real-time incremental in-memory transformations, enabling batch and stream processing with the same pipeline, performing stateful operations efficiently, and customizing data processing pipelines.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
