ljn
Comparisons
Compares Flink alternatives for real-time ClickHouse integration.
Written by
Armend Avdijaj
-

Introduction
Modern data architectures demand real-time processing capabilities that can handle massive volumes while delivering insights within milliseconds. ClickHouse is increasingly gaining momentum for analytical workloads, and so teams increasingly need reliable streaming solutions that integrate seamlessly with this high-performance columnar database.
While Apache Flink can be thought of as the industry standard for stream processing, many organizations encounter significant challenges when integrating it with ClickHouse; the simple reality is that it's a tool with a steep learning curve, and too many features that most teams would not even use under this context, while at the same time lacking key features that make the pairing more problematic than ideal.
This article explores practical alternatives to Flink for ClickHouse integration, specifically addressing:
Connection reliability and performance
Setup and maintenance realities
Team expertise requirements
Scalability under real-world conditions
1. Business Case: Global Retail Chain's Real-time Inventory System
1.1 The Challenge: Keeping Inventory Accurate Across Channels
Imagine a global retail chain operating 2,000+ physical stores alongside multiple e-commerce platforms and mobile apps. Each channel generates thousands of inventory transactions per minute—purchases, returns, transfers, and stock adjustments.
The business problem: inventory discrepancies causing both stockouts (lost sales) and overstock situations (tied-up capital). When a customer orders online for in-store pickup, they often arrive to find the item unavailable, despite the system showing positive inventory.
These disconnects rise from data latency issues—inventory updates taking minutes or hours to propagate across systems, rather than seconds. For high-velocity items during promotional periods, even a few minutes of delay can mean dozens of angry customers.
1.2 Technical Requirements
The retailer already has a nice Kafka event collection layer capturing all inventory-related transactions across their system. Building on this foundation, their technical team has outlined the following requirements for the new real-time inventory solution:
Processing at least 50,000 transactions per minute during peak periods (e.g., Black Friday, holiday season, etc).
Sub-second inventory visibility across all channels.
Dynamic pricing adjustments based on current inventory levels and velocity.
Complex business rules for promotional pricing and bundles.
Historical analytics for inventory optimization.
Minimal latency between Kafka event collection and ClickHouse availability.
High reliability with no data loss during peak periods.
Consistent deduplication to ensure accurate inventory counts.
Exactly-once processing guarantees for financial accuracy.
In the diagram below we can see their current architecture, where multiple data sources feed into the Kafka event collection layer, which then connects to processing components and ultimately to the ClickHouse storage system:
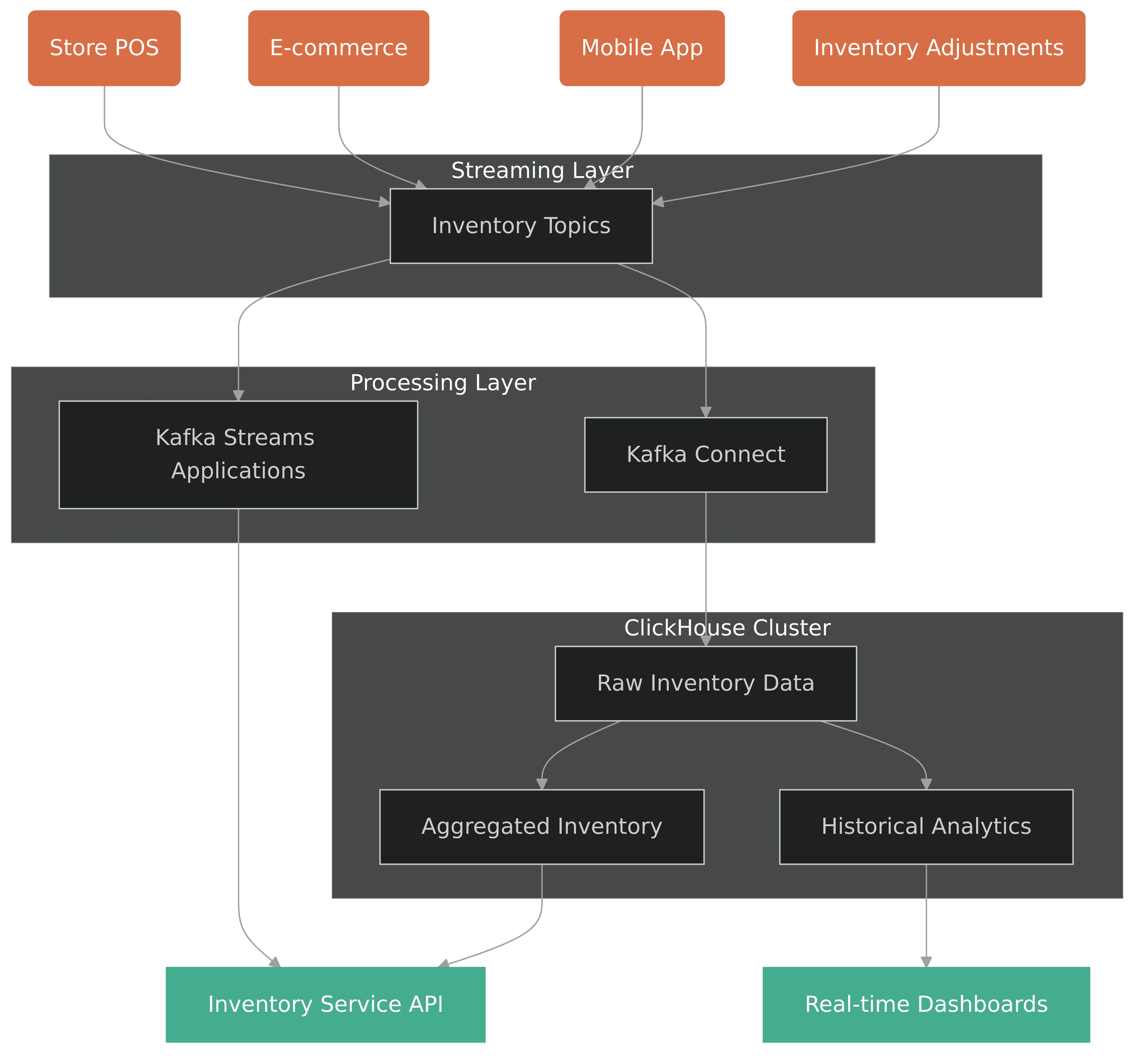
1.3 Why Flink Isn't Working Well
The retailer initially implements Apache Flink for this use case but runs into several roadblocks:
Development bottlenecks: Every change requires specialized Java engineers, creating dependency on a small team.
Operational complexity: The Flink cluster demands constant tuning and monitoring, with unpredictable performance spikes when writing to ClickHouse.
Resource intensive: Memory and CPU requirements balloon during high-traffic periods.
Integration challenges: Custom code needed for ClickHouse sink connector optimization.
Maintenance overhead: Version upgrades require extensive testing and often break existing pipelines.
2. Evaluation Framework: What Matters Most
2.1 Integration Capabilities
When evaluating alternatives to Flink for ClickHouse integration, four critical factors determine success:
Kafka connector reliability: Most retail environments use Kafka as their messaging backbone. The connector must handle backpressure gracefully while maintaining exactly-once semantics.
ClickHouse write performance: The alternative must optimize batch sizes, write frequencies, and connection pooling for ClickHouse's specific architecture.
Data transformation flexibility: Retail inventory requires complex transformations—aggregations across time windows, joins with product metadata, and state management for calculating stock levels.
Retail-specific operations: Support for inventory-specific needs like duplicate detection (preventing double-counting), late event handling, and order-aware processing.
2.2 Setup and Maintenance Reality
Beyond technical capabilities, operational considerations often determine long-term success:
Initial deployment complexity: How much specialized knowledge is required to get the system running? Can it leverage existing infrastructure?
Day-to-day operational requirements: What ongoing maintenance is needed? How frequently does the system need tuning?
Scaling characteristics: How does the solution handle unexpected traffic spikes? Can it scale elastically?
Open source vs. cloud options: Does the team prefer self-managed infrastructure or managed services? What are the cost implications?
Monitoring and troubleshooting: How observable is the system? Can issues be diagnosed quickly during peak retail periods?
2.3 Team Requirements
The human factor is often overlooked, but critical for success:
Technical skill prerequisites: What languages and frameworks must the team know? Is specialized training required?
Learning curve assessment: How quickly can the team become productive? Are there familiar concepts to build upon?
Support ecosystem quality: Is help available when needed? How active is the community? Are there commercial support options?
So, now that we know the key factors that make a solution feasible, what is to be done?
Let us take a look at 5 distinct alternatives and what each one offers.
3. Apache Spark Structured Streaming
3.1 ClickHouse Connectivity
Spark Structured Streaming offers robust ClickHouse integration through its JDBC connector, with several advantages over Flink:
Native batch-to-stream unification simplifies development, using the same DataFrame API for both patterns.
More mature JDBC driver support with connection pooling optimization.
Better handling of ClickHouse's specific bulk insert patterns.
Simpler backpressure management when ClickHouse write capacity is exceeded.
However, there are tradeoffs:
Lacks specialized ClickHouse connector (unlike some Flink implementations).
Requires careful configuration to optimize write batching.
Checkpoint management needs tuning for ClickHouse's constraints.
The following example demonstrates connecting Spark Structured Streaming to ClickHouse for inventory data. This can be done using Spark from Scala directly, or the Python Spark API:
3.2 Getting Started: Setup Process
Spark's setup process differs from Flink in several important ways:
Infrastructure footprint: Spark typically requires fewer nodes for equivalent workloads, with more efficient resource sharing.
Configuration simplicity: Less specialized tuning required for basic operations.
Deployment options: More mature container support with better Kubernetes integration.
Local development: Superior local testing capabilities with the same code running in development and production.
A typical Spark-ClickHouse setup involves:
Deploying a Spark cluster (standalone, YARN, Kubernetes, or cloud-managed).
Configuring the JDBC connector with appropriate batching parameters.
Implementing the processing pipeline using Spark's DataFrame/Dataset API.
Setting up checkpointing with appropriate ClickHouse-compatible settings.
Configuring monitoring using Spark's web UI and metrics system.
Common pitfalls include:
Inadequate checkpoint cleanup (leading to disk space issues).
Inefficient batch sizes for ClickHouse (too small causes connection overhead, too large causes memory problems).
Improper watermark settings causing late-arriving data issues.
Insufficient error handling for ClickHouse connection failures.
Compared to Flink, Spark's setup is generally more approachable for teams with existing data engineering experience, though it still requires careful configuration for production use.
3.3 Retail-Critical Features
going back to our example, for retail inventory management, Spark Structured Streaming provides some advantages:
Time-window operations: More intuitive API for calculating moving averages of sales velocity.
Join performance: Better memory management for joining inventory events with product metadata.
Deduplication: Built-in dropDuplicates() functionality with flexible window options.
State management: More transparent stateful operations for tracking inventory levels.
However, there are also limitations compared to Flink:
Less sophisticated event-time processing for late-arriving data
Higher latency (typically milliseconds vs. microseconds)
Less granular control over state backend options
For our retail inventory use case, these tradeoffs generally favor Spark unless sub-millisecond latency is required.
But what about scalability? How this all translate to heavy workloads under heavy demand?
3.4 Scaling for Black Friday and Beyond
Spark shows competitive throughput benchmarks with ClickHouse, particularly for the write-heavy patterns of retail inventory:
Handling peak loads: Effectively processes 100,000+ inventory transactions per minute with proper tuning.
Resource consumption: More efficient CPU utilization, though higher memory requirements.
Elastic scaling: Better dynamic allocation capabilities for handling flash sales.
A key advantage for retail scenarios is Spark's ability to dynamically adjust resources during traffic spikes without restarting the application, a critical feature during high-volume sales events.
3.5 Is Your Team Spark-Ready?
Successfully implementing Spark Structured Streaming for ClickHouse integration requires reasonable skill:
Core skills: Scala or Python proficiency, SQL knowledge, distributed systems understanding.
Learning curve: Moderate for teams with data processing experience, steeper from scratch.
Team structure: Typically requires fewer specialists than Flink, with better skill transferability from batch processing.
The typical learning path involves:
Starting with DataFrame/Dataset basics.
Adding streaming concepts.
Optimizing checkpoint and state management.
Fine-tuning ClickHouse integration.
Most teams can become productive with Spark Structured Streaming in 1-2 months—roughly half the time typically needed for Flink proficiency when working with ClickHouse.
4. Kafka-Native Solutions
4.1 Kafka Streams
4.1.1 ClickHouse Integration Capabilities
Kafka Streams offers a good alternative for teams already invested in Kafka, with several ClickHouse integration approaches:
Using the JDBC Sink Connector with ClickHouse-specific configuration.
Implementing a custom Processor API solution for optimized writes.
Leveraging the Kafka Connect framework with specialized ClickHouse connectors.
These approaches provide:
Strong consistency guarantees with exactly-once semantics.
Native handling of Kafka's partitioning scheme for parallelized ClickHouse writes.
Simple deployment alongside existing Kafka infrastructure.
The main limitations compared to Flink include:
Less mature connector ecosystem specifically for ClickHouse.
More manual optimization required for high-throughput scenarios.
Limited built-in monitoring for ClickHouse write performance.
4.1.2 Setup & Operations
How do Kafka Streams stand when compared to Flink?
Infrastructure reuse: Leverage existing Kafka brokers without additional cluster components.
Simplified deployment: Applications deploy as standard JVM applications or containers.
Reduced monitoring scope: Fewer moving parts means fewer failure points.
Consistent upgrade path: Version compatibility follows Kafka's well-defined compatibility guidelines.
The following example shows a basic Kafka Streams application writing inventory data to ClickHouse:
Here, the clickHouseWriter component handles the actual connection to ClickHouse, typically using batch inserts and connection pooling for the best performance.
4.2 ksqlDB
4.2.1 SQL for Stream Processing
ksqlDB is not a direct standalone streaming solution per se; it's a database for building stream processing applications on top of Apache Kafka. For teams seeking the fastest path to production, this approach offers a SQL-based approach to stream processing with several advantages:
Familiar SQL syntax dramatically reduces learning curve.
Declarative approach simplifies common inventory aggregations.
Built-in functions for time-based operations and state management.
Visual tools for query building and monitoring.
This SQL familiarity translates to significant productivity advantages:
Enabling analysts to contribute directly to stream processing logic.
Reducing implementation time for common retail analytics patterns.
Simplifying maintenance and troubleshooting.
However, ksqlDB also comes with limitations:
Less flexible than programmatic approaches for complex logic.
Fewer optimization options for performance-critical scenarios.
Limited support for complex transformations and custom functions.
And of course, there's the fact that ksqlDB uses Kafka for stream processing, which might or might not be desirable for some teams.
4.2.2 ClickHouse Connection
ksqlDB provides several options for connecting to ClickHouse:
Using Kafka Connect with the JDBC Sink Connector.
Implementing a custom connector with the Connect API.
Using third-party connectors like the Confluent ClickHouse Sink.
The integration process requires specific attention to:
Data type mapping: Ensuring compatible conversions between ksqlDB and ClickHouse types.
Write patterns: Configuring batch sizes and flush intervals for optimal performance.
Schema evolution: Managing how schema changes propagate to ClickHouse tables.
A sample ksqlDB to ClickHouse integration for inventory tracking would look like such:
4.3 Handling Retail-Scale Data
Kafka-native solutions show distinct performance characteristics with ClickHouse integration:
Kafka Streams: Handles 30,000-50,000 events per second per node with proper tuning.
ksqlDB: Typically processes 10,000-20,000 events per second per node for simple transformations.
If we're thinking on our use case in terms of scaling strategies, these solutions provide:
Horizontal scaling by increasing partition count and consumer instances.
Careful key distribution to prevent hotspots during flash sales.
Stateful processing optimization for inventory counting.
Compared to Flink, Kafka-native approaches generally provide:
Simpler scaling for predictable workloads.
Less flexible optimization for complex processing.
Better integration with existing Kafka infrastructure.
More straightforward monitoring and troubleshooting.
The key limitation for high-scale retail implementations is typically in the ClickHouse sink configuration rather than the processing capacity itself.
4.4 Team Profile for Success
The team requirements for Kafka-native approaches differ significantly from Flink:
Kafka Streams: Requires Java knowledge but with a simpler API than Flink; moderate learning curve.
ksqlDB: Requires SQL skills with minimal streaming knowledge; very gentle learning curve.
Most retail organizations find the learning path considerably shorter:
SQL developers can become productive with ksqlDB in days to weeks.
Java developers typically master Kafka Streams in 2-4 weeks.
Monitoring and operations knowledge transfers easily from existing Kafka deployments.
This accessibility makes Kafka-native solutions particularly appealing for retail organizations with limited specialized streaming expertise.
5. Apache Pulsar
5.1 Connecting to ClickHouse
Apache Pulsar is yet another streaming alternative that is more feature-rich than Kafka. If Kafka is a firehose for raw throughput, Pulsar is a Swiss Army Knife better suited for complex enterprise scenarios requiring diverse messaging patterns and tighter guarantees.
Pulsar offers a different architectural approach to stream processing with both built-in and external options for ClickHouse integration:
Pulsar IO Framework: Provides connector infrastructure with developing ClickHouse support
Pulsar Functions: Enables lightweight processing with custom ClickHouse client code
Pulsar SQL: Allows querying streams using SQL with JDBC sink possibilities
The performance characteristics are as follows:
Superior throughput for multi-tenant scenarios with namespace isolation.
Better handling of backpressure from ClickHouse during write spikes.
More consistent latency profiles under varying load.
Unlike Flink or Kafka Streams, Pulsar's design separates storage and compute layers, which offers unique advantages when integrating with ClickHouse:
More stable write patterns even during broker scalability events.
Better isolation between processing tenants in multi-department retail environments.
Simplified backpressure handling when ClickHouse cannot keep up.
5.2 Setup Experience
Pulsar's initial deployment complexity sits between Flink (climbing Everest) and Kafka Streams (maybe climbing a slightly smaller mountain):
Requires multiple components: brokers, bookies, ZooKeeper (being phased out).
More moving parts than Kafka but with better multi-tenant isolation.
Growing cloud-managed options reducing operational complexity.
The operational overhead presents a mixed picture:
More components to monitor than Kafka-native solutions.
Better built-in monitoring and observability than Flink.
Admin-friendly interface with more intuitive configuration.
But Pulsar's most unique aspect is its unique learning curve:
New concepts around topics, subscriptions, and namespaces.
Growing but still limited community resources compared to Kafka or Flink.
Improving but sometimes inconsistent documentation quality.
For retail organizations already managing complex infrastructure, Pulsar's additional components may not represent a significant burden, while its multi-tenant capabilities can be valuable for large retailers with separate departments (e.g., grocery vs. electronics inventory).
5.3 Feature Set for Retail Use Cases
Pulsar provides several features that can result relevant to retail inventory management:
Deduplication: Native message deduplication prevents duplicate inventory counts.
Multi-topic subscriptions: Simplifies joining inventory data across different channels.
Delayed message delivery: Enables sophisticated promotional rules for flash sales.
Tiered storage: Allows cost-effective retention of historical inventory data.
For particularly complex retail scenarios, Pulsar offers:
Built-in exactly-once processing guarantees.
Better handling of late events with more flexible subscription models.
Superior schema management for evolving inventory models.
Function-based processing with ClickHouse integration looks like:
5.4 Scalability Profile
Pulsar's scalability model provides several advantages for retail scenarios:
Horizontal scaling: Independent scaling of broker and storage layers.
Elastic consumption: Better handling of traffic spikes without reconfiguration.
Multi-datacenter replication: Simplified disaster recovery for global retailers.
Load balancing: Native message redistribution during scaling events.
When integrated with ClickHouse, we can get:
Consistent throughput during scaling operations.
Better isolation of processing resources for priority inventory transactions.
More efficient resource utilization under varying load.
The key limitations compared to Flink include:
Less mature ecosystem for complex processing.
Fewer optimization options for specialized workflows.
Steeper learning curve for operations teams.
For large retailers with global operations and multi-regional ClickHouse deployments, Pulsar's geo-replication capabilities may outweigh these limitations.
5.5 Required Team Expertise
Successfully implementing Pulsar with ClickHouse requires:
Core skills: Java or Python knowledge, messaging concepts understanding, distributed systems familiarity.
Learning investment: Significant for teams without messaging experience, medium for those with Kafka background.
Operations expertise: More specialized than Kafka but with better isolation guarantees.
The team profile that succeeds with Pulsar typically includes:
Engineers familiar with messaging systems concepts.
Operations staff comfortable with multi-component systems.
Development teams willing to invest in a newer but potentially more powerful architecture.
6. Redpanda
6.1 ClickHouse Integration
Finally, we arrive at Redpanda, a managed Kafka API-compatible streaming platform. This alternative offers unique advantages for ClickHouse integration:
Kafka protocol compatibility means existing Kafka connectors work without modification.
Better write throughput characteristics with less tuning required.
More efficient resource utilization leading to smaller cluster footprints.
Simplified client configuration with fewer workarounds needed.
Example configuration for Redpanda to ClickHouse using Kafka Connect:
6.2 Operations Considerations
Redpanda offers operational advantages compared to Flink:
Deployment simplicity: Single binary deployment with no external dependencies reduces initial setup complexity.
Built-in monitoring: Native Prometheus metrics provide visibility into system behavior.
Reduced JVM considerations: No garbage collection tuning or JVM configuration required.
Configuration parameters: Fewer configuration parameters than Kafka, simplifying initial deployment.
However, when we go into production environments, there are some points we need to consider:
Resource requirements: While marketing materials suggest three i3en.6xlarge instances for 1GB/s workloads, Redpanda's own documentation recommends five i3en.12xlarge instances—a 3.3x increase in resources.
Drive management: Random I/O patterns require careful drive over-provisioning (beyond the standard 10%) to prevent performance degradation during extended operations.
Monitoring requirements: Additional monitoring of NVMe drive performance metrics becomes essential, as drive-level issues significantly impact system performance.
Performance variability: Greater sensitivity to workload characteristics requires more careful capacity planning than alternatives.
For retail organizations evaluating operational complexity, these factors should be incorporated into both initial sizing and ongoing maintenance plans, particularly for mission-critical inventory processing.
6.3 Retail Processing Capabilities
Redpanda leverages the Kafka API ecosystem for processing capabilities:
With Kafka Streams: Stateful operations, windowing, and joins with familiar APIs.
With ksqlDB: SQL interface for simpler inventory analytics queries.
With custom consumers: Direct integration options for specialized needs.
For retail inventory scenarios, Redpanda offers:
Low initial latency: Good performance for simple workloads during initial operation.
API compatibility: Easy migration from existing Kafka-based processing pipelines.
Exactly-once semantics: Support for critical inventory consistency guarantees.
However, retail workloads have specific characteristics that impact performance:
Variable producer counts: Performance degrades significantly when increasing from few producers (4) to many (50)—common in multi-channel retail environments.
Record key requirements: Order processing typically requires record keys for message ordering, which testing shows reduces Redpanda throughput by up to 34%.
Recovery capabilities: Testing shows limitations in draining backlogs after consumer outages while under sustained producer load.
So Redpanda would be indeed viable for some retail use cases with carefully controlled workloads, but organizations should test thoroughly with production-like scenarios including multi-channel inputs and ordering requirements, before committing to the solution completely.
6.4 Handling Scale
Redpanda's scale characteristics with ClickHouse show strengths and limitations:
Initial throughput: Can achieve high throughput with carefully optimized workloads and limited producers.
Optimized conditions: Performs well under specific benchmark conditions with large message batches.
Operational simplicity: Reduced configuration complexity compared to alternatives.
Some aspects to consider:
Workload variability: Performance may be sensitive to changes in producer count, message key distribution, and batch sizes. Configuration that works optimally in one scenario might not translate to others.
Extended operation stability: Latency profiles during initial deployment may differ significantly from those observed after continuous operation over multiple days. Thorough validation should include extended performance monitoring.
Storage subsystem utilization: While modern NVMe drives offer substantial throughput capabilities, actual utilization may vary between platforms. Organizations should validate resource efficiency under their specific workloads.
Retention cycle impacts: As systems reach data retention limits and begin removing older segments, performance characteristics can change. Production-ready deployments should account for this normal operational state rather than empty-drive conditions.
These considerations are especially relevant for retail inventory systems, where workload patterns shift during seasonal peaks and reliable performance is required through extended high-volume periods.
6.5 Team Requirements
The team profile for Redpanda success remains one of its advantages:
Required knowledge: Kafka API familiarity transfers directly.
Learning investment: Minimal for teams with Kafka experience.
Operational expertise: Lower initial barrier to entry than Flink.
Some considerations for production teams:
Performance tuning expertise: Greater sensitivity to workload characteristics requires deeper understanding of performance tuning.
NVMe drive knowledge: Teams need expertise in SSD performance characteristics and monitoring.
Capacity planning skills: More conservative sizing approaches needed than benchmark results suggest.
Extended testing capabilities: Ability to conduct long-running tests (12+ hours) becomes essential for accurate performance prediction.
For retail organizations with existing Kafka expertise, Redpanda offers a familiar pathway with reduced initial complexity, though sustained production operation requires additional skills beyond those needed for Kafka.
6.6 Production Performance Monitoring Considerations
When evaluating streaming platforms for ClickHouse integration, several critical performance factors deserve close attention during proof-of-concept phases:
Long-term operation stability: Monitor performance metrics over extended periods (multiple days rather than hours). Modern NVMe drives undergo background maintenance processes that may interact differently with various I/O patterns, potentially affecting latency profiles over time.
Retention cycle behavior: Establish monitoring specifically during retention cycles when the system begins removing older segments. Performance characteristics during these regular maintenance periods can differ significantly from initial deployment metrics when storage is largely empty.
Workload pattern impacts: Validate performance across the full spectrum of expected production conditions. Pay particular attention to scenarios with varying producer counts, message batch sizes, and record key distribution patterns typical in multi-channel retail environments.
Resource utilization patterns: Implement comprehensive monitoring beyond basic throughput and latency metrics. Track disk I/O patterns, memory pressure, and CPU utilization to identify potential resource bottlenecks under sustained load.
For mission-critical inventory systems, these validation steps will help ensure that initial benchmark results translate reliably to production environments. Consider implementing a phased deployment approach that gradually increases traffic volume while carefully monitoring these key indicators.
7. Building a Retail Inventory Pipeline
7.1 Choosing the Right Alternative
Selecting the optimal streaming solution for ClickHouse integration requires a structured assessment approach. For our retail inventory use case, we must evaluate alternatives based on four critical dimensions:
Technical fit: Does the solution provide the necessary features for complex inventory management?
Operational complexity: Can the team effectively deploy and maintain the solution?
Performance under retail conditions: Will the solution handle seasonal spikes and promotional events?
Team readiness: Does the organization have or can it acquire the skills needed?
For this global retail chain, we've identified key priorities that guide our decision:
Minimizing data latency between transaction capture and availability in ClickHouse
Supporting complex inventory calculations across channels
Ensuring reliable performance during peak shopping periods
Reducing operational complexity compared to their current Flink implementation
Leveraging existing team skills where possible
After careful evaluation, we recommend a hybrid approach using Kafka Streams for processing with either Kafka or Redpanda as the messaging layer, depending on specific organizational constraints:
Kafka offers proven performance stability across diverse workloads, particularly for extended operations with record keys and during retention cycles, though with higher initial configuration complexity.
Redpanda provides operational simplicity and good performance for specific workloads, though requires careful validation under production-like conditions over extended periods.
For organizations prioritizing long-term performance stability and predictability across varied workload patterns, particularly during peak retail periods, Kafka may provide more consistent results. For those prioritizing operational simplicity with more controlled workloads, Redpanda offers advantages worth exploring.
7.2 Solution Architecture
The proposed architecture balances operational requirements with performance needs:
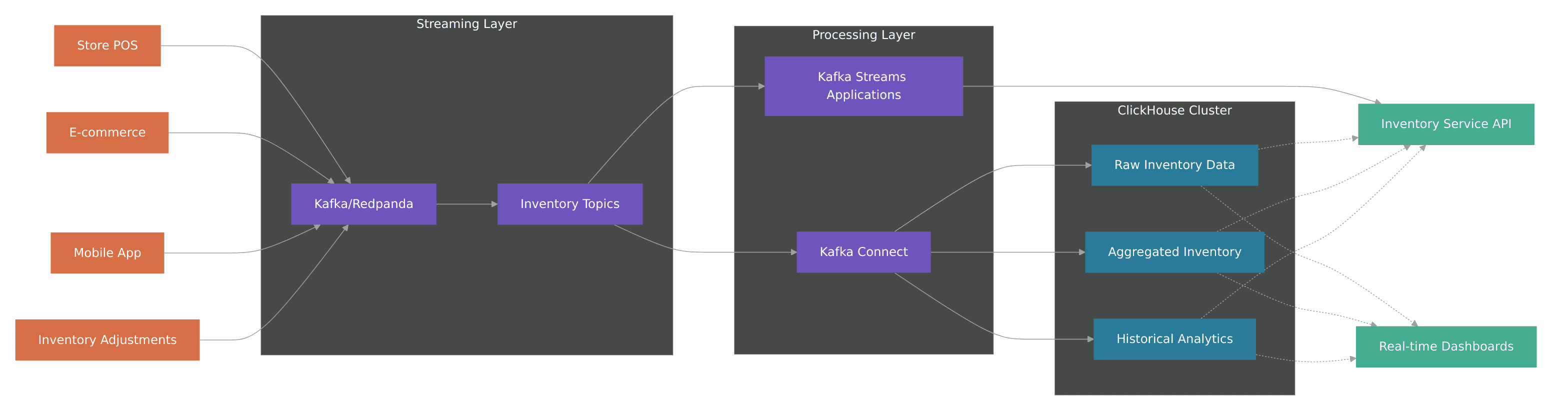
This architecture addresses several key components:
Data ingestion: Multiple retail channels feed data into streaming topics, which serve as the unified source of truth.
Stream processing: Kafka Streams applications handle the core business logic, including:
Inventory level calculations across channels.
Promotional inventory management.
Stock allocation and reservation logic.
Dynamic pricing adjustments.
ClickHouse integration: Kafka Connect provides optimized, fault-tolerant data delivery to ClickHouse.
Service layer: API and dashboard components consume processed data from both streaming and ClickHouse layers.
Critical design considerations include:
Appropriate sizing: Ensuring adequate capacity for sustained operation during peak periods, not just initial benchmark conditions.
Circuit breakers: Implementing protection mechanisms between components to prevent cascading failures.
Tiered storage: Structuring ClickHouse tables for optimal performance with recent vs. historical data.
Monitoring instrumentation: Comprehensive observability focused on long-term performance patterns, retention cycles, and resource utilization.
For resilient operation, we recommend implementing comprehensive performance validation across extended time periods (minimum 48-72 hours) with production-representative workloads before finalizing platform selection and sizing decisions.
7.3 Implementation Steps
7.3.1 Data Flow Setup
Implementing this architecture requires careful coordination across multiple components. The initial setup focuses on configuring a resilient data flow from retail sources to ClickHouse:
Streaming platform configuration:
Design topic structure with appropriate partition counts for both average and peak throughput
Establish retention policies aligned with business recovery requirements
Implement comprehensive monitoring for lag detection across the entire pipeline
Configure resource allocation to accommodate extended high-volume periods
Kafka Streams application deployment:
Deploy on Kubernetes with resource quotas that allow for scaled operation
Implement exactly-once processing semantics with appropriate checkpoint intervals
Create robust error handling with dead-letter queues for failed processing
Design state stores with adequate capacity for transaction history and recovery
ClickHouse integration optimization:
Configure Kafka Connect workers with appropriate parallelism and resource allocation
Implement connection pooling with timeout and retry parameters optimized for ClickHouse
Develop idempotent write patterns to prevent duplicate data during recovery scenarios
Establish backpressure mechanisms that protect ClickHouse during high-volume periods
Extended validation protocol:
Begin with component-level testing using synthetic data at moderate volumes
Progress to multi-day production-scale testing with representative data patterns
Simulate failure scenarios at each component boundary (source outages, ClickHouse slowdowns)
Conduct parallel processing using both existing and new pipelines for direct comparison
Critically, test performance during data retention operations when segment deletion occurs
This implementation approach emphasizes resilience at transition points, allowing for graceful degradation rather than cascading failures when components experience stress.
7.3.2 Processing Logic
The inventory management logic implemented in Kafka Streams remains consistent regardless of the underlying messaging platform. The core implementation handles stateful calculations required for real-time inventory tracking:
This implementation incorporates essential features for retail inventory management:
Transaction deduplication: Prevents inventory miscounts during reprocessing scenarios
Stateful processing: Maintains current inventory levels with fault-tolerant recovery
Business logic encapsulation: Isolates inventory calculation rules for maintainability
Event-driven updates: Publishes state changes immediately for downstream consumption
For managing data integrity across multiple retail channels, we implement these additional safeguards:
Time-windowed transaction processing with configurable lateness tolerance
Periodic reconciliation comparing transactional data with batch-calculated totals
Automated correction workflows that generate adjustment transactions when discrepancies occur
Circuit breakers that prevent cascading failures when components experience stress
These mechanisms ensure system resilience during network issues, component outages, and unexpected data patterns—common challenges in multi-channel retail environments.
7.3.3 ClickHouse Integration Details
ClickHouse table design significantly impacts query performance and write efficiency. Our tiered approach optimizes for both:
For the Kafka Connect configuration for ClickHouse integration:
Some details to pay attention to regarding configuration parameters:
Batch sizing: Balancing throughput requirements with recovery capabilities.
Connection management: Properly sized connection pools with appropriate timeouts.
Error handling: Comprehensive dead-letter queuing with automated recovery mechanisms.
Monitoring instrumentation: Detailed metrics collection for each stage of the process.
7.4 Scaling Strategy
Retail inventory systems face unique scaling challenges, particularly during seasonal events when traffic can surge 10-15× above baseline. Our scaling approach focuses on predictability and resilience:
Capacity assessment methodology:
Establish baseline metrics during normal operations
Conduct extended load tests with representative seasonal traffic patterns
Model resource requirements under various backlog scenarios
Validate performance during segment deletion and retention operations
Test system recovery with simulated component failures
Proactive scaling triggers:
Implement early warning indicators for resource constraints
Monitor both infrastructure metrics and business KPIs
Establish performance SLOs with appropriate thresholds
Create automated scaling policies with manual override capabilities
Multi-dimensional scaling strategy:
Scale streaming platform nodes based on throughput and retention requirements
Adjust Kafka Streams application instances proportional to processing complexity
Optimize Kafka Connect worker allocation based on ClickHouse write capacity
Scale ClickHouse resources according to query patterns and data volume
The most effective approach combines predictive and reactive scaling mechanisms. By analyzing historical patterns and seasonal trends, we pre-provision resources 24-48 hours before anticipated traffic surges, then fine-tune based on actual observed patterns.
For organizations with significant seasonal variations, we recommend maintaining detailed performance profiles that correlate business metrics (orders per minute, unique items sold) with technical metrics (throughput, latency, resource utilization). This correlation provides the foundation for capacity planning that balances performance and cost optimization across the entire business cycle.
8. Side-by-Side Comparison
8.1 Feature Matrix
After evaluating alternatives across technical, operational, and team dimensions, we can compare Flink alternatives for ClickHouse integration:
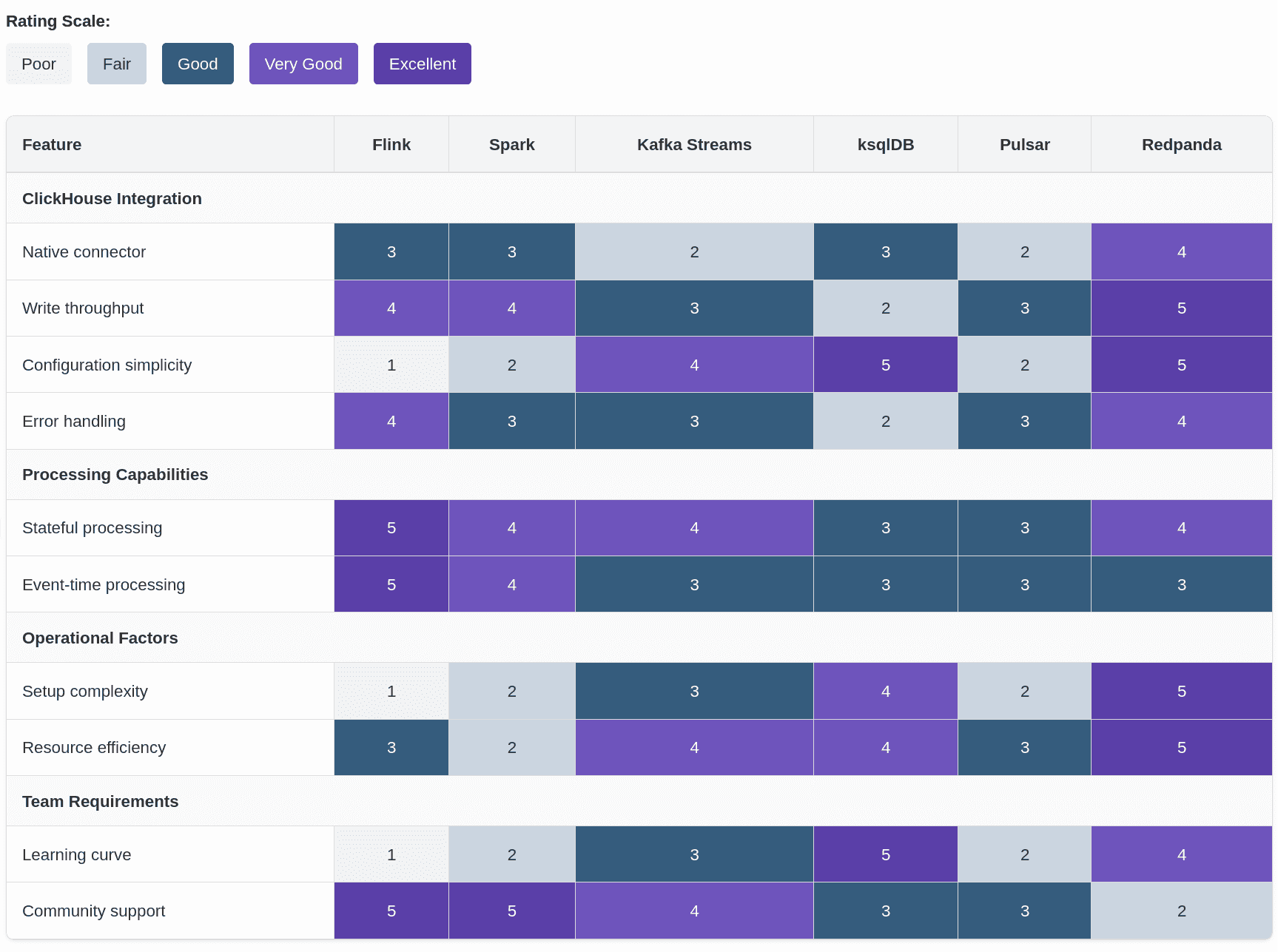
This comparison highlights several important insights:
Flink leads in processing capabilities but with higher operational complexity.
Redpanda excels in operational simplicity and ClickHouse integration while maintaining competitive processing.
ksqlDB offers the gentlest learning curve with more limited processing capabilities.
Spark provides the most mature ecosystem with good balance across categories.
For retail inventory workloads, Redpanda's operational simplicity and strong ClickHouse integration make it particularly compelling despite its smaller community.
8.2 Operational Assessment
Real-world operational considerations are critical when selecting a streaming platform:
Framework | Setup Complexity | Day-to-Day Maintenance | Production Reliability | Monitoring Maturity | Upgrade Path |
|---|---|---|---|---|---|
Flink | High: Requires cluster setup with JobManager, TaskManager, ZooKeeper, HDFS/S3 for checkpoints | High: Ongoing checkpoint management, savepoint creation, tuning | Medium: More frequent stalls when ClickHouse write capacity exceeded | High: Comprehensive metrics but requires extensive dashboarding | Complex: Version upgrades often require application changes |
Spark | Medium-High: Core Spark cluster with proper executor sizing | Medium: Resource allocation management and rebalancing | Medium-High: Better backpressure handling but higher resource consumption | High: Mature Web UI and metrics | Medium: Well-defined upgrade process but requires testing |
Kafka Streams | Low: Runs as standard Java applications | Low-Medium: Standard JVM application maintenance | High: Superior isolation between processing and persistence | Medium: Leverages Kafka metrics with stream-specific additions | Simple: Follows Kafka client compatibility rules |
ksqlDB | Low: Deployed alongside Kafka Connect workers | Low: Managed through Kafka Connect processes | Medium: Limited by SQL processing capabilities | Medium: Standard Kafka monitoring plus SQL-specific metrics | Simple: Managed as part of Kafka Connect upgrades |
Pulsar | High: Multiple components including brokers, bookies, ZooKeeper | Medium-High: Regular BookKeeper maintenance, segment compaction | High: Separate storage layer improves fault isolation | Medium: Comprehensive but less mature dashboarding | Medium-Complex: Multi-component upgrade coordination |
Redpanda | Very Low: Single binary deployment, minimal configuration | Very Low: Automated topic compaction, minimal intervention | Very High: Designed for operational simplicity with ClickHouse | High: Built-in Prometheus metrics with dashboards | Simple: Rolling updates with minimal configuration changes |
The retail inventory use case prioritizes operational simplicity and reliability during peak periods—areas where Redpanda excels compared to Flink.
8.3 Team Impact
The human factor often determines project success more than technical capabilities. Each alternative places different demands on the team:
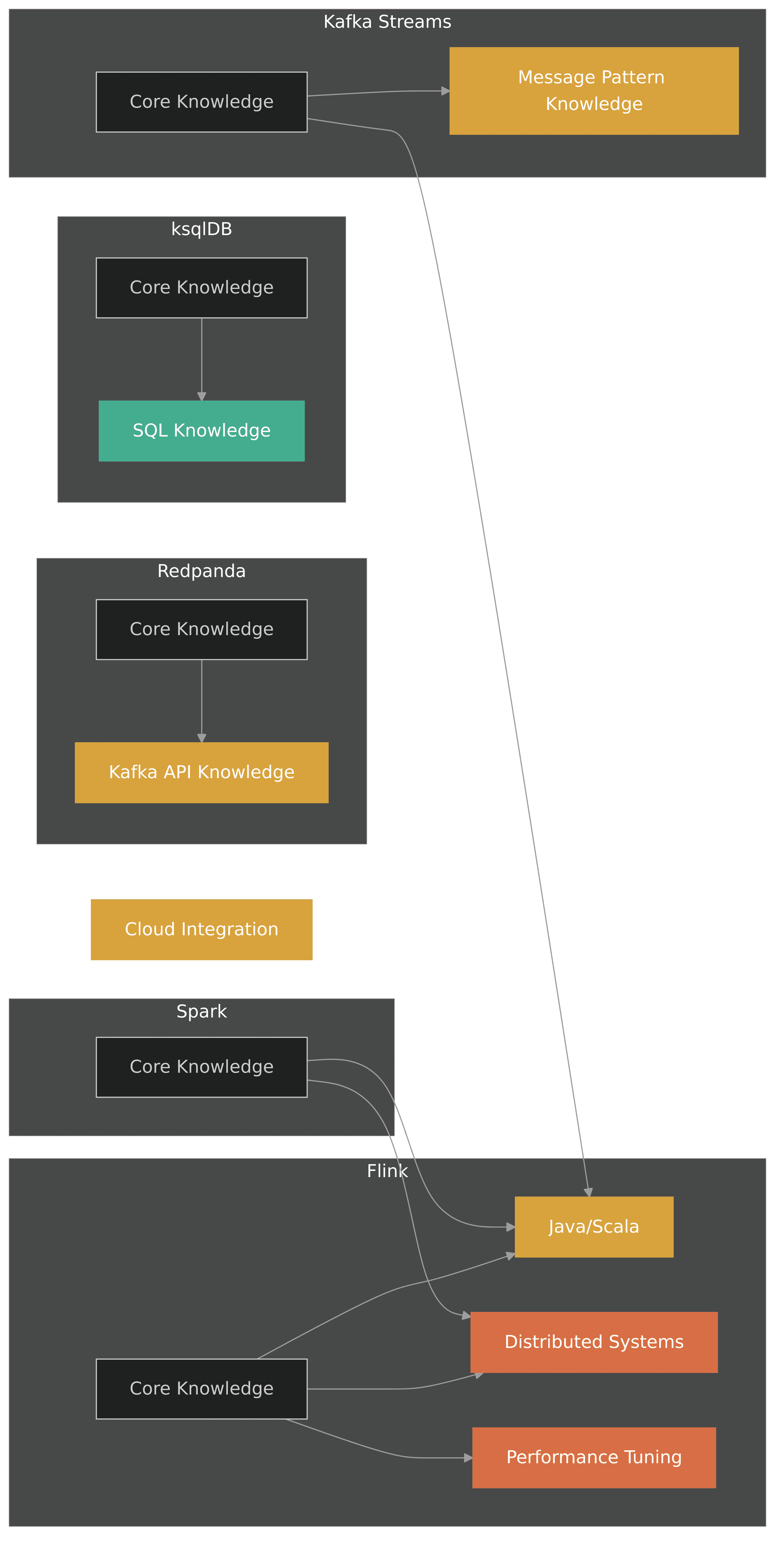
Team requirements vary significantly by platform:
Development team skill requirements:
Flink: Java/Scala expertise, distributed systems knowledge, specialized streaming concepts
Spark: Similar skills with focus on batch processing concepts
Kafka Streams: Java knowledge with simpler APIs
ksqlDB: Primarily SQL skills with minimal programming expertise
Redpanda: Leverages existing Kafka API knowledge
Operations team considerations:
Flink: Specialized knowledge for checkpoint management, savepoints, cluster scaling
Pulsar: Experience with BookKeeper operations and multi-layer architecture
Redpanda: Minimal specialized knowledge beyond basic system administration
Spark: Experience with executor management and resource allocation
For retail organizations with diverse technical teams and high staff turnover, solutions with gentler learning curves like ksqlDB and Redpanda offer significant advantages.
9. Decision Framework
9.1 Best Fit Scenarios
Based on our analysis, each alternative shows clear strengths for specific ClickHouse integration scenarios:
Flink makes sense when:
Processing logic involves complex event patterns and sophisticated state management.
Sub-second processing latency is essential.
Team has deep Java expertise and streaming experience.
Organization can support specialized operational knowledge.
Spark Structured Streaming makes sense when:
Unified batch and streaming processing is required.
Team has existing Spark expertise.
Processing includes complex analytical operations.
Integration spans both ClickHouse and HDFS/cloud storage.
Kafka Streams makes sense when:
Organization has existing Kafka deployment.
Processing logic is moderate in complexity.
Team has Java development capabilities.
Operational simplicity is valued.
ksqlDB makes sense when:
Simple transformations and aggregations are sufficient.
Team lacks specialized programming expertise.
Time-to-production is the primary concern.
SQL familiarity is widespread in the organization.
Pulsar makes sense when:
Multi-tenant isolation is required.
Geo-replication is a critical requirement.
Organization values storage-compute separation.
Team can manage operational complexity.
Redpanda makes sense when:
Operational simplicity is paramount
Kafka API compatibility is needed
High performance is required with minimal tuning
Resources for specialized streaming expertise are limited
For our retail inventory use case, Redpanda with Kafka Streams provides the optimal balance of technical capability, operational simplicity, and team accessibility.
9.2 Working Within Constraints
Most organizations face constraints that limit their technology options. Here's how to navigate common limitations:
Skill constraints:
If Java expertise is limited, prioritize ksqlDB or managed solutions.
When SQL knowledge dominates, ksqlDB offers the smoothest transition.
For teams with Kafka experience, Redpanda minimizes new learning.
Budget considerations:
Open source solutions require operational investment.
Infrastructure costs vary significantly:
Flink typically requires 30-50% more resources than Kafka Streams.
Redpanda shows 40-60% lower resource requirements than Kafka.
Spark incurs higher memory overhead but potentially fewer nodes.
Operational costs often exceed infrastructure expenses in the long run.
Migration complexity:
From existing Flink: Spark offers the most similar programming model.
From Kafka-based systems: Redpanda provides the smoothest transition.
From batch-oriented workflows: Spark enables gradual migration.
Timeline pressures:
For rapid deployment (1-2 months): ksqlDB or Redpanda.
For moderate timelines (2-4 months): Kafka Streams or managed Spark.
For comprehensive rewrites (4+ months): Flink or Pulsar.
The following decision flow can guide selection based on key constraints:
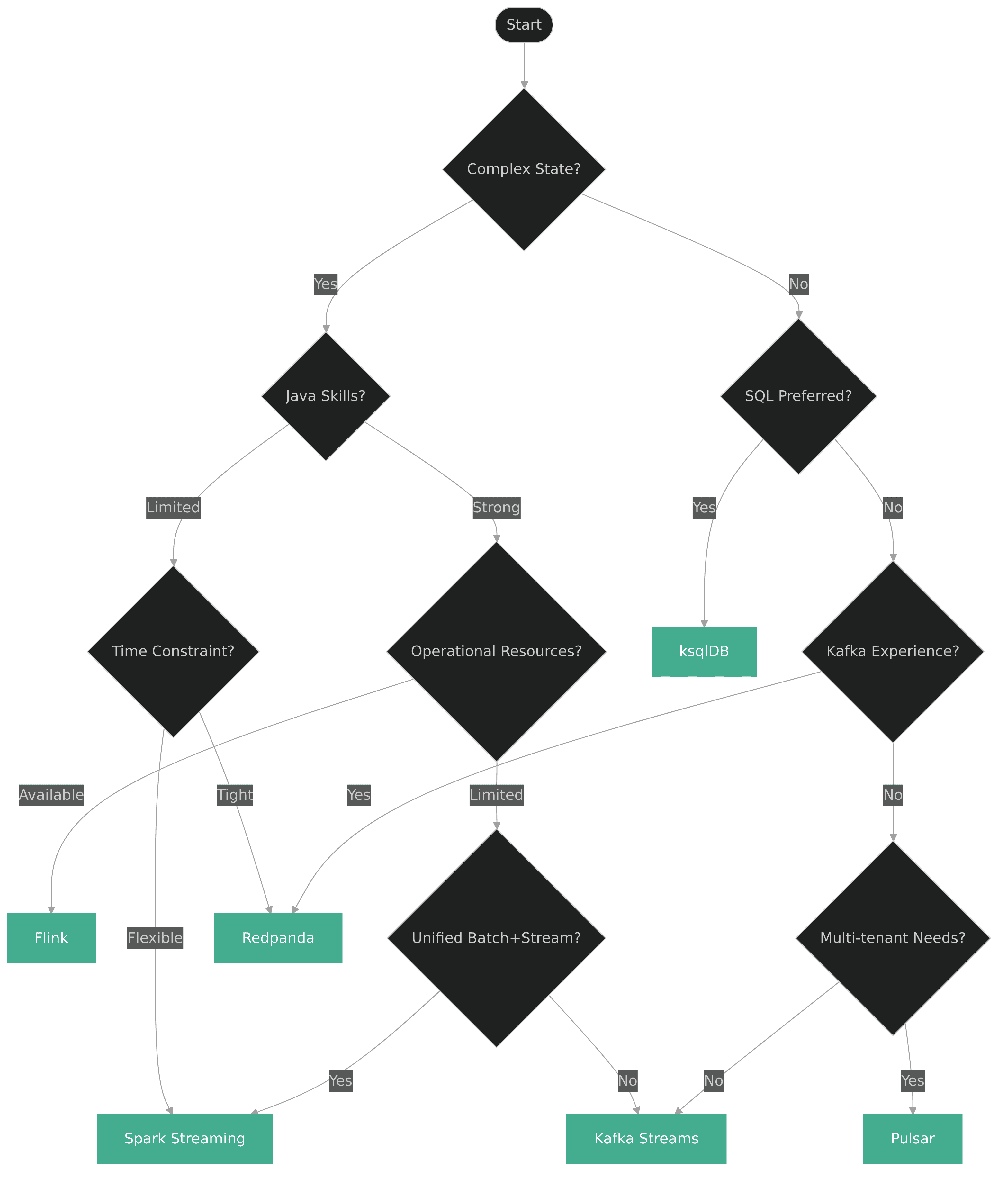
For our retail inventory case with moderate complexity, limited specialized streaming expertise, and significant operational constraints, Redpanda emerges as the strongest fit.
10. Final Thoughts
Moving data to ClickHouse in real time differs significantly from batch processing. Our evaluation shows that while Flink offers superior processing capabilities, its operational complexity creates massive challenges for many teams. Alternatives like Redpanda deliver a better balance; strong ClickHouse integration with much lower operational overhead.
For retail inventory management such as our worked example, simpler solutions often provide more business value than technically superior but complex frameworks. The best choice depends on team skills, existing systems, and performance needs.
At GlassFlow we're working on addressing these challenges with a no-nonsense Python-native streaming solution. Our approach aims to eliminate JVM dependencies and complex cluster management while providing seamless integration with ClickHouse. We believe the Python ecosystem offers the right balance of accessibility and power for modern data teams.
Try GlassFlow Open Source for ClickHouse on GitHub!
When selecting a solution, prioritize end-to-end integration quality over individual features. The ability to reliably deliver data to ClickHouse under varying load conditions matters more than advanced capabilities that are difficult to implement and maintain.
11. References
Kleppmann, M. (2023). "Designing Data-Intensive Applications." O'Reilly Media.
Narkhede, N., Shapira, G., & Palino, T. (2022). "Kafka: The Definitive Guide." O'Reilly Media.
Dunning, T., & Friedman, E. (2021). "Streaming Systems." O'Reilly Media.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
